データのクレンジング #
データのクレンジングとは、データ品質向上のための処理で、欠損値、異常値、重複データなどを修正・削除することです。
Node-AIでAIモデルを作成するには以下の条件を満たす必要があります。
- 欠損値が存在しない
- String (文字列)型のカラムが存在しない=全て数値データである
前者の場合は 欠損値補間カード、 後者の場合は 文字列置換カードで対応することができます。
ただし、今回のデータは統計量を見た通り欠損値が存在せず、文字列型のカラムも存在しないため、少なくとも最低限データ分析に必要なクレンジングの必要はありません。
また、このような最低限のクレンジング以外にも 移動平均カード等の予測精度を上げるためのクレンジングもあります。
データの分割 #
AIモデルを作成し、評価するために元のデータを学習データと評価データ(テストデータ)に分割します。ここで、学習データとは、AIモデルを学習させるためのデータであり、評価データとは、学習させたAIモデルの性能を評価するためのデータです。
さて、 データ分割カード を利用して学習データと評価データに分割してみましょう。
なお、これ以降に設置するカードは
公開レシピ(回帰レシピ)を利用することで一括で設定することもできます。
詳細はこちら
機械学習では過学習を防ぐため学習データと評価データを分割して利用することは一般的です。 チュートリアル内容と関連する 3.1. データ分割もご参照ください。
データ分割カードの配置・結線 #
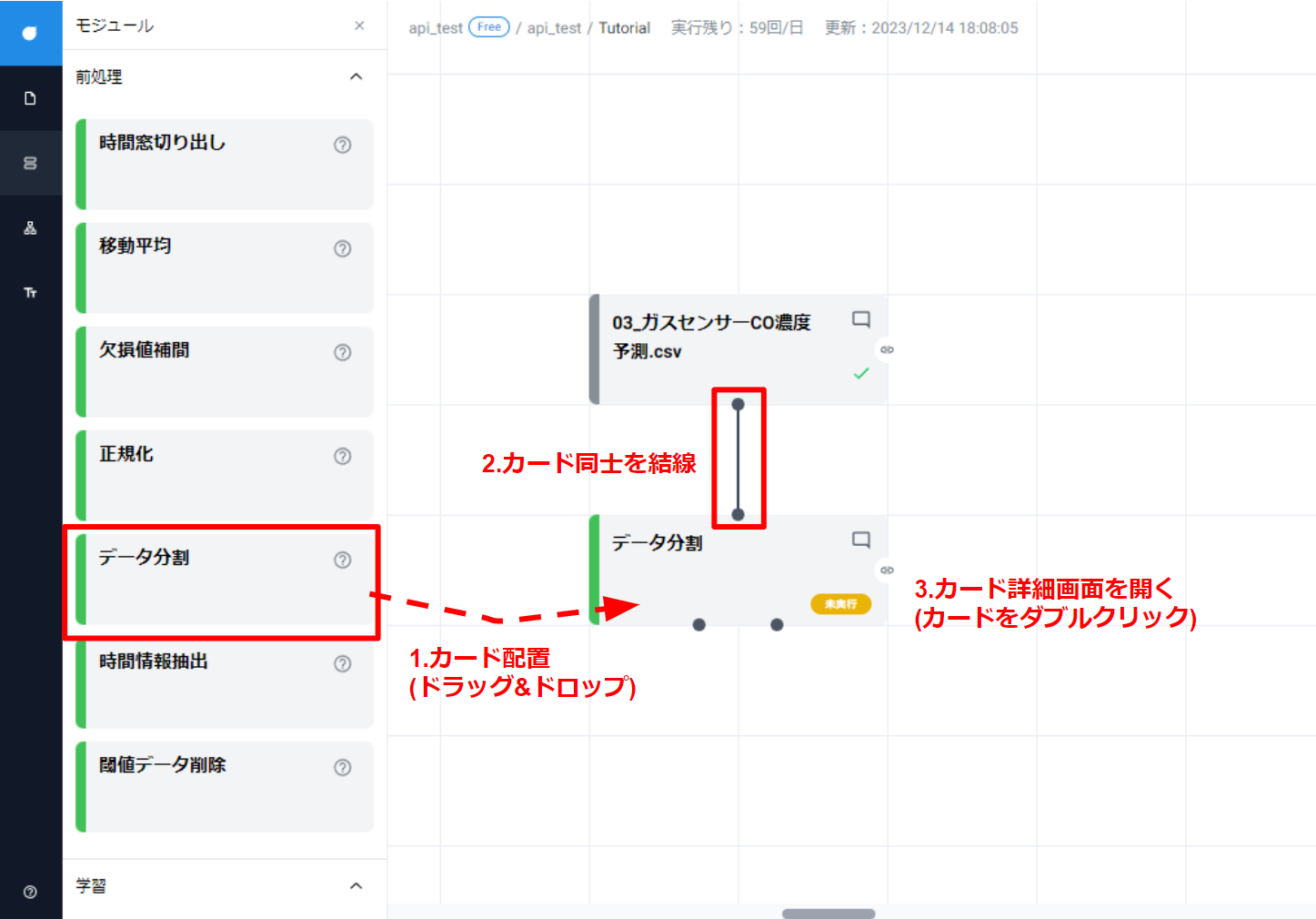
- “モジュールツール” パネルから “データ分割カード” をドラッグし、キャンバスでドロップして配置します。
- 最初に配置した Gas_sensor のデータカードのコネクタからドラッグし、データ分割のコネクタに結線します。
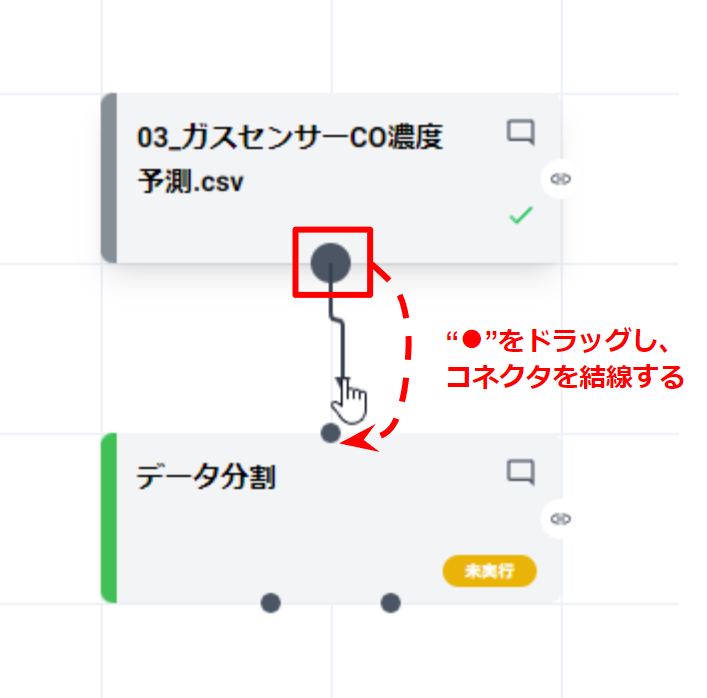
- データ分割カードをダブルクリックしてカードを開きます(カード詳細画面が表示されます)。
学習データ(Train Data)とテストデータ(Test Data)の設定 #
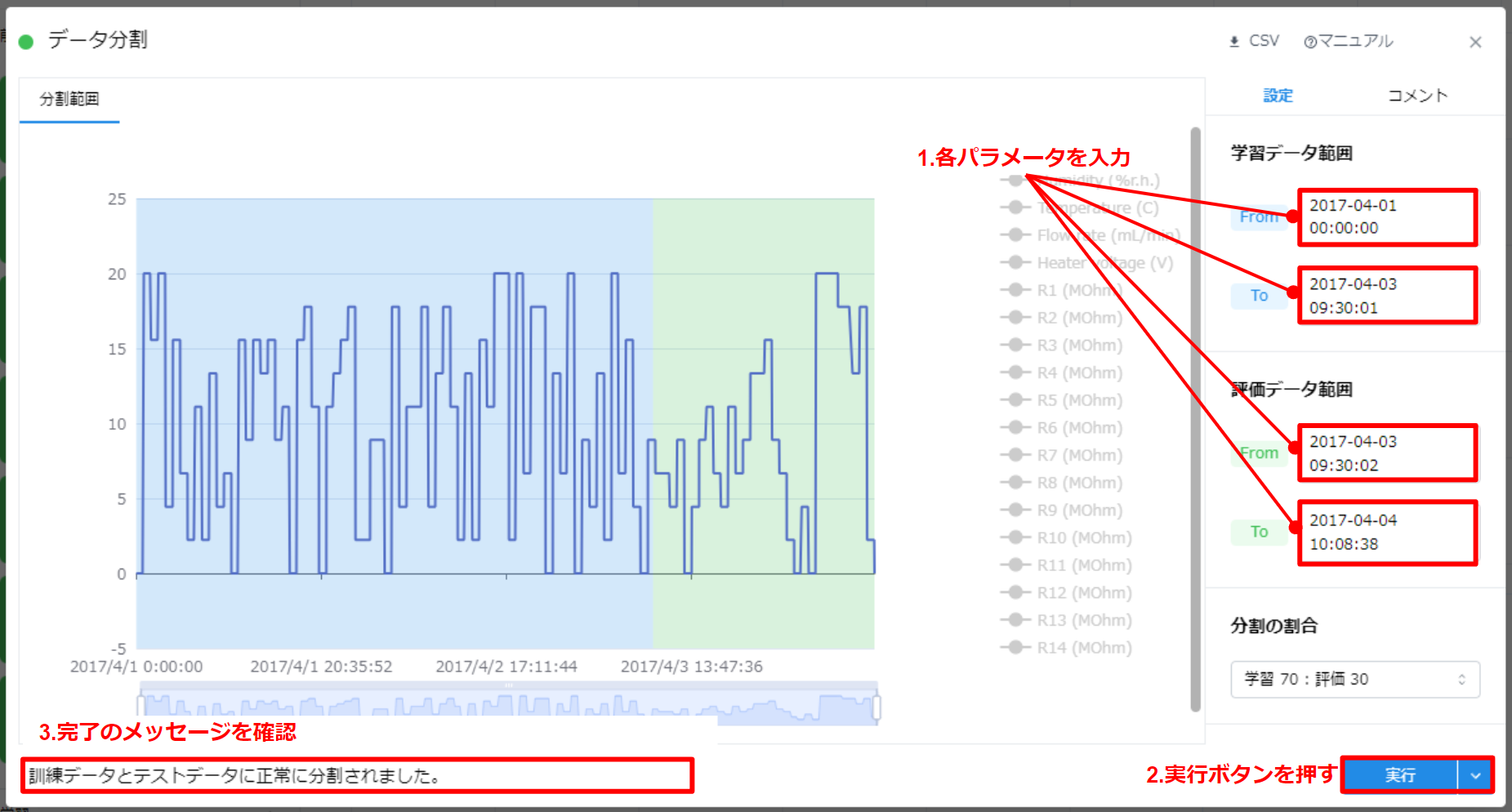
- 以下の設定を入力します。(初期値として入力された状態にあります)
学習データ範囲
- From: 2017-04-01 00:00:00
- To: 2017-04-03 09:30:01
評価データ範囲
- From: 2017-04-03 09:30:02
- To: 2017-04-04 10:08:38
- “実行” ボタンを押します。
- 処理が完了すると、画面左下部に完了のステータスが表示されます。
データの分割が実行されたあとは、カード下の 2 つのコネクタから別々にデータを引き出せるようになります。
データの正規化 #
正規化とはデータの不均一性を無くし過学習を防ぐための変換です。
詳細はこちら
チュートリアル内容と関連する 1.6. 正規化もご参照ください。
一般的に正規化とは、学習データに対しては学習データ自身の平均と標準偏差を利用して、評価データに対しては学習データの平均と標準偏差を利用して正規化を行います。 Node-AI ではこれを実現するために コンフィグリンク機能を利用します。
正規化カードの配置 #
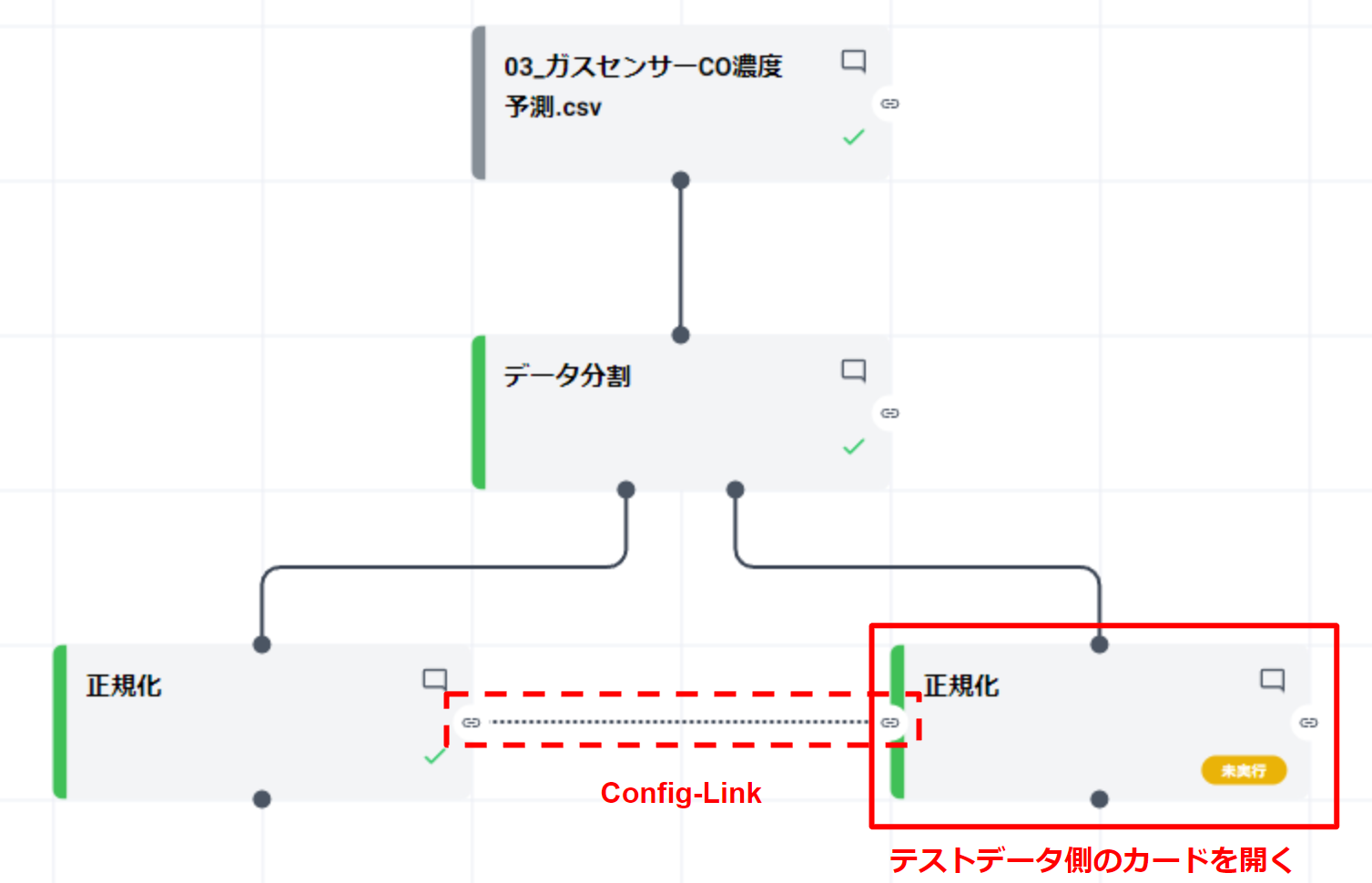
正規化カードを、学習データ、テストデータ用にそれぞれ配置し、各カードを結線します。
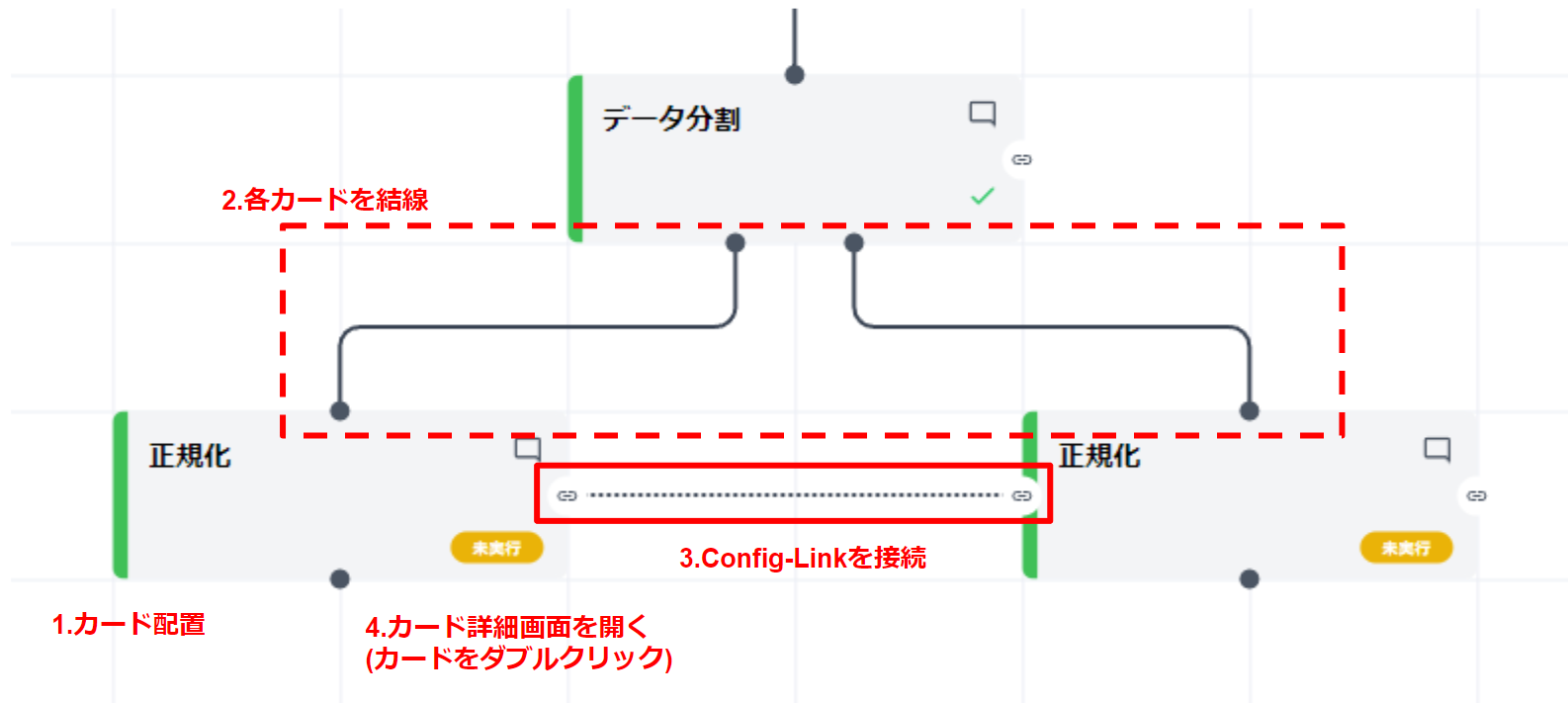
- “学習データ” と “テストデータ” 用に正規化カードを配置します。
- 各カードを学習データとテストデータへ結線します。
- 学習データ用のカードとテストデータ用カードでコンフィグリンクを接続します。(カードの横方向を結線をします)

- 学習データ用のカードを開きます。
正規化カードの実行 #
学習データ用の正規化カードを設定して実行します。

- “標準化” を選択します。
- “実行” ボタンを押します。データが正規化(平均 0、標準偏差 1)されます。
正規化結果の確認 #
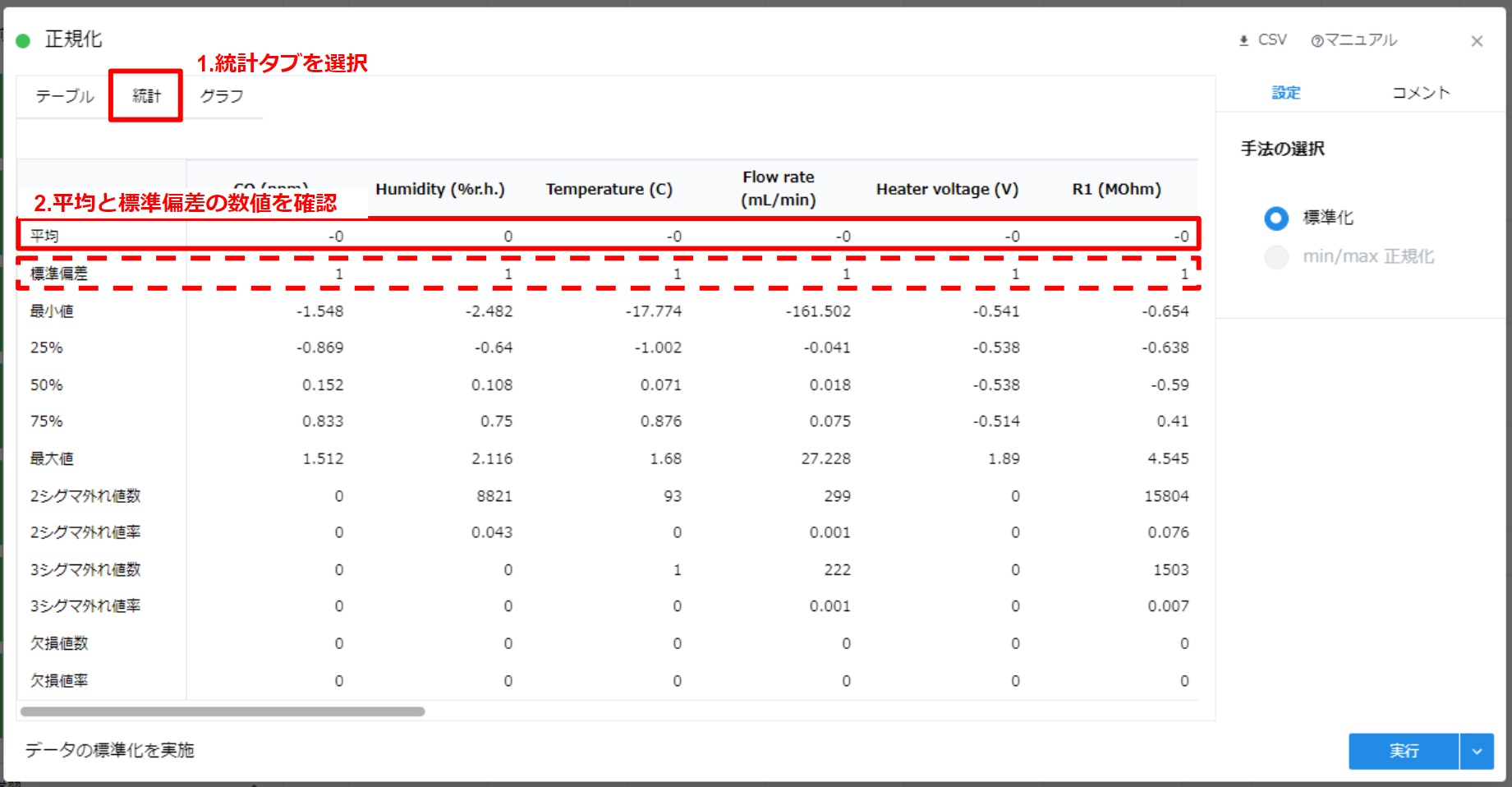
- “統計” タブを選択します。
- “平均” が 0, “標準偏差” が 1 になっていることがわかります。
テスト用データの正規化 #
- “設定” パネルからコンフィグリンクで共有された各項目の値が確認できます。(上図は CO の値を開いて確認した例)

- “実行” ボタンを押します。(学習データの平均と標準偏差を利用して評価データが正規化されます)
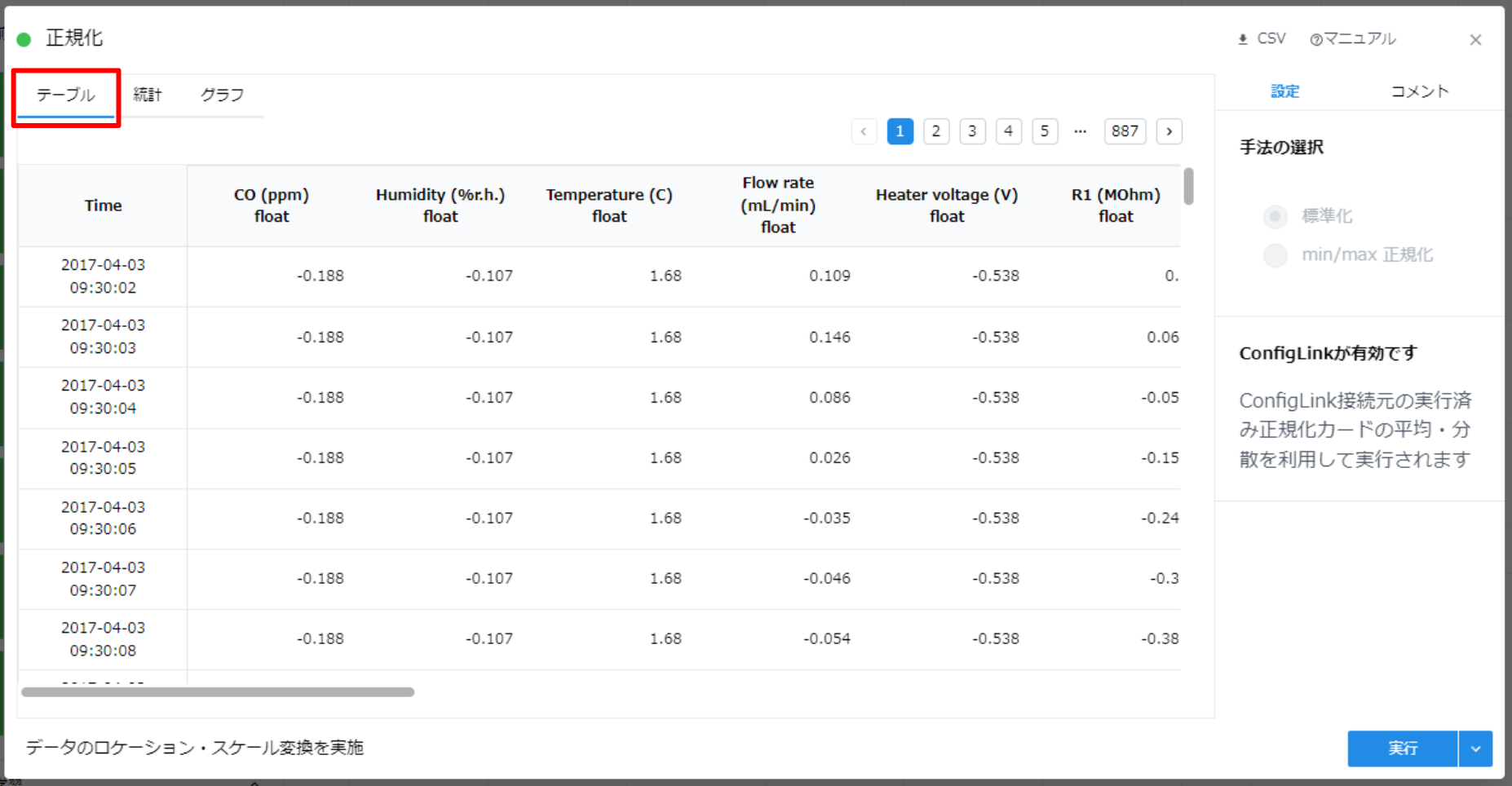
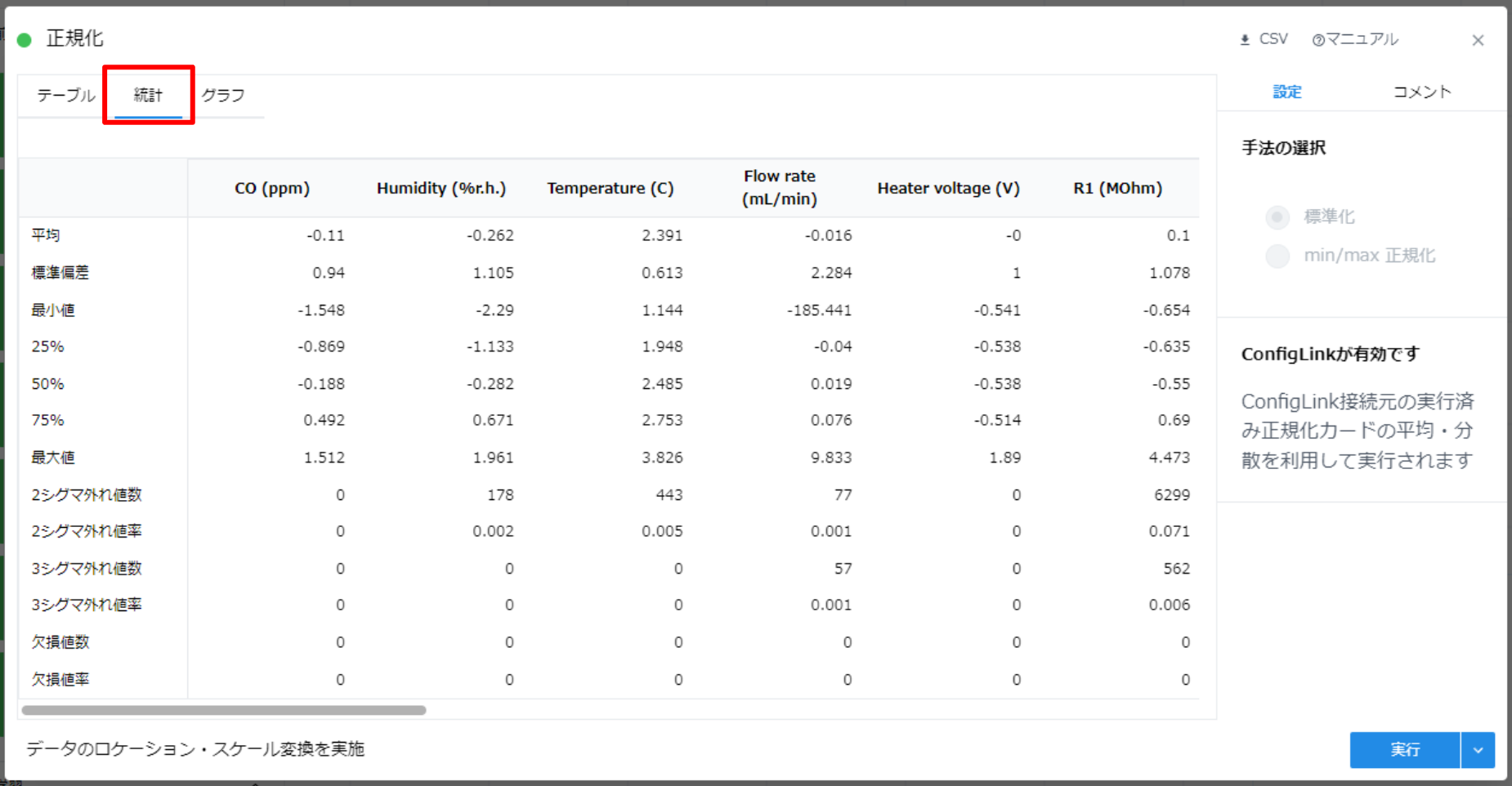
処理完了後は “テーブル” タブ、 “統計” タブは上図のように表示されます。
詳細はこちら
テストデータの正規化後の平均と標準偏差が 0, 1 から少し外れているのは学習データの平均と標準偏差を利用してテストデータの正規化を行なっているためです。 “統計” タブを開くと、各カラムの平均と標準偏差は概ね 0, 1 付近に収まっていますが学習データとはややずれた値を持っています。
時間窓の切り出し #
時系列データをAIモデルで学習させるためには、元のデータを “時間窓” と呼ばれる細切れのデータに切り出す必要があります。
時間窓切り出しデータの配置 #
時間窓切り出しカードを、学習データ、テストデータ用にそれぞれ配置し、各カードを結線します
- 学習データとテストデータ用に時間窓切り出しカードを配置し、各カードを結線します。(コンフィグリンク含む)
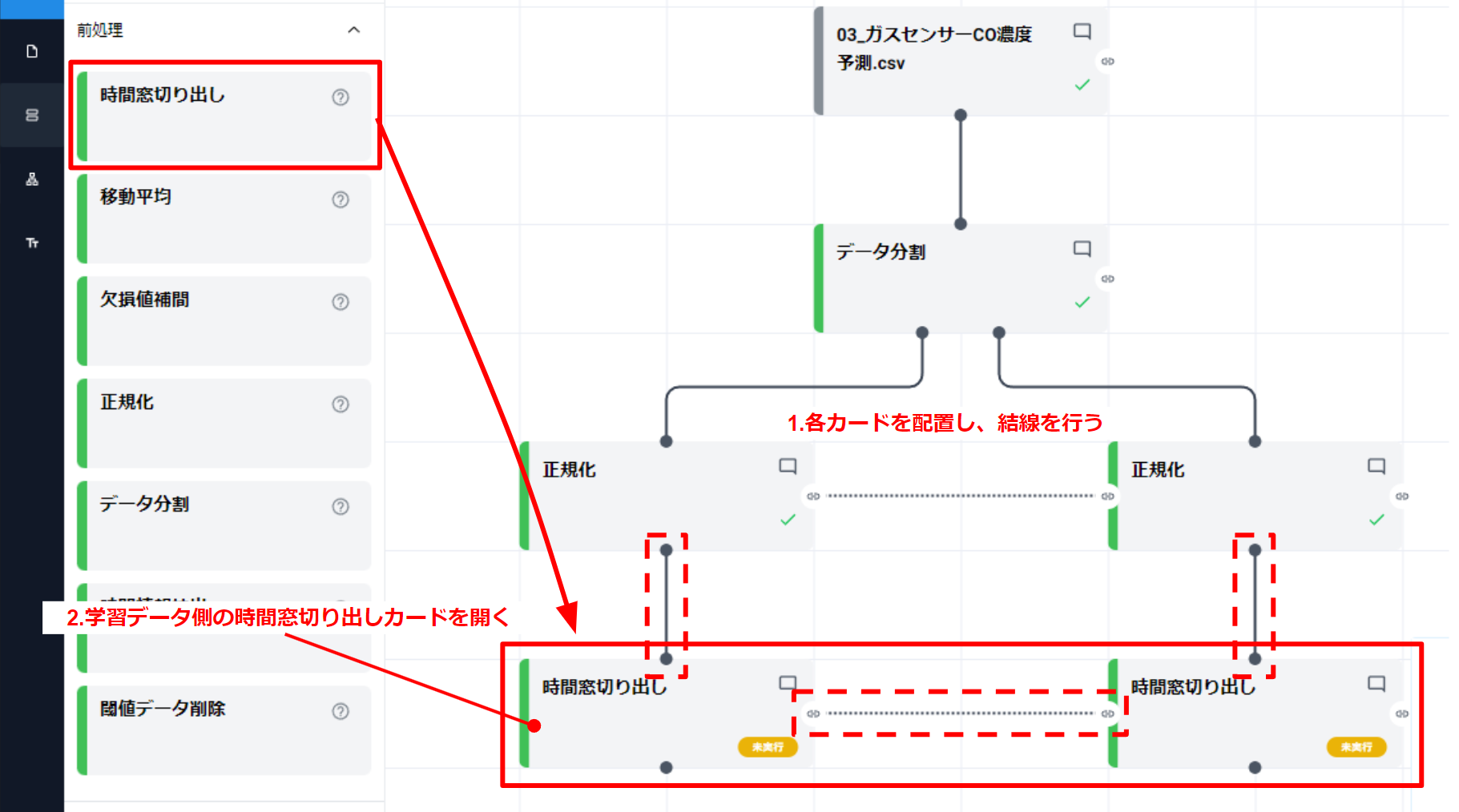
- 学習データの時間窓切り出しカードを開きます。
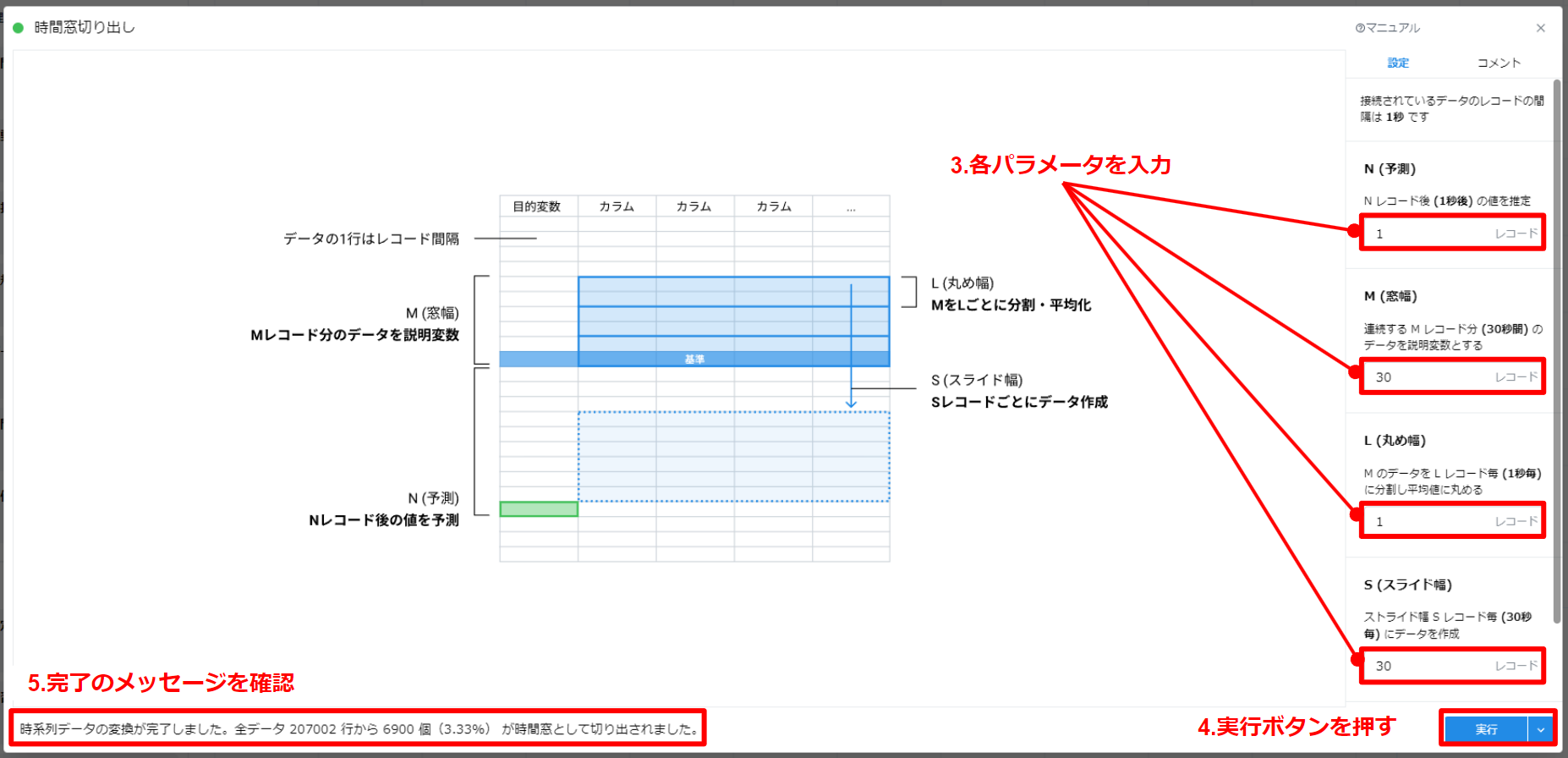
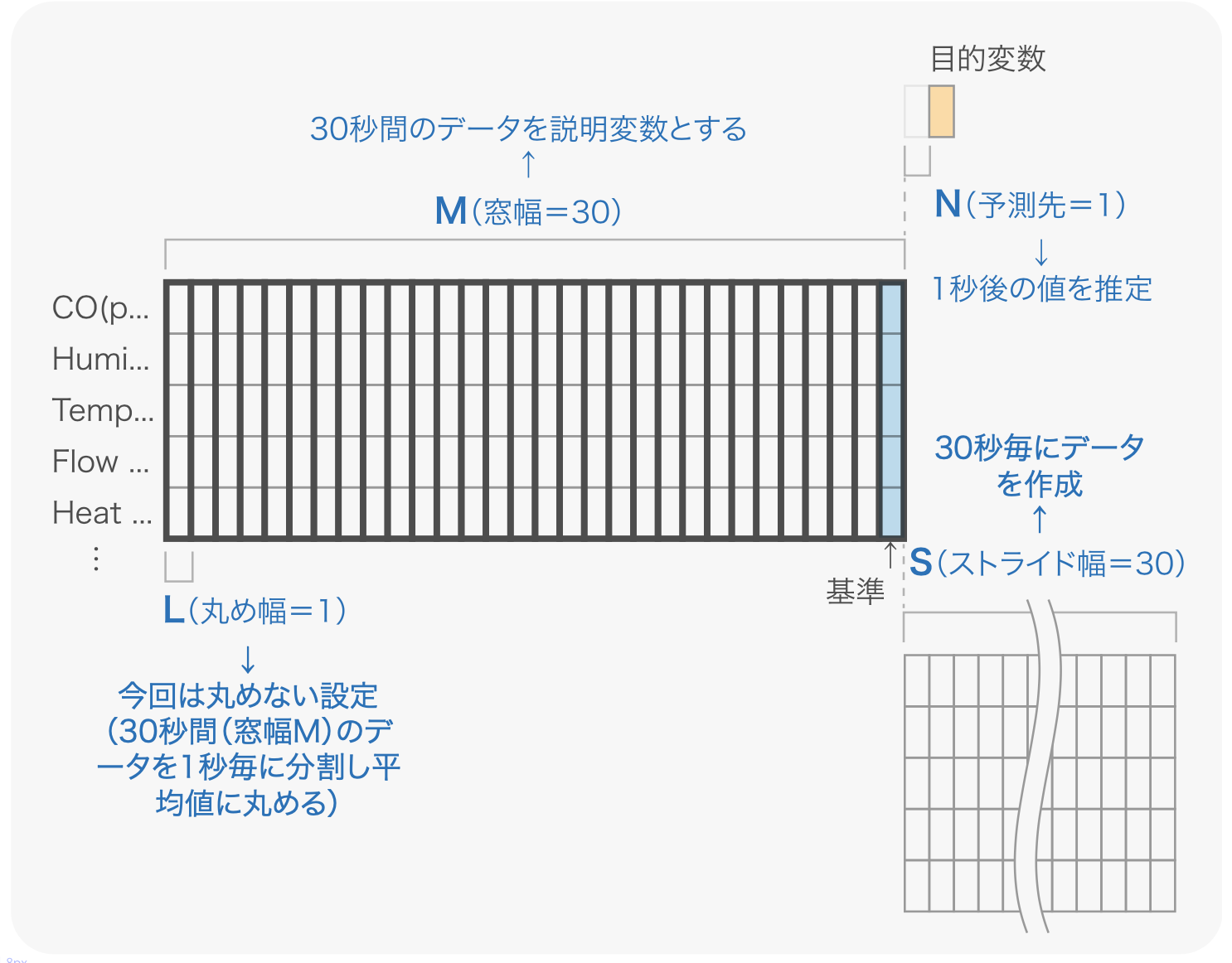
- “設定” パネルを以下のように入力します。
| 項目 | 設定値 |
|---|---|
| N: 予測先 | 1 |
| M: 窓幅 | 30 |
| L: 丸め幅 | 1 |
| S: ストライド幅 | 30 |
- “実行” ボタンを押します。
- 処理が完了するとステータスが表示されます。
詳細はこちら
テストデータの時間窓切り出し #
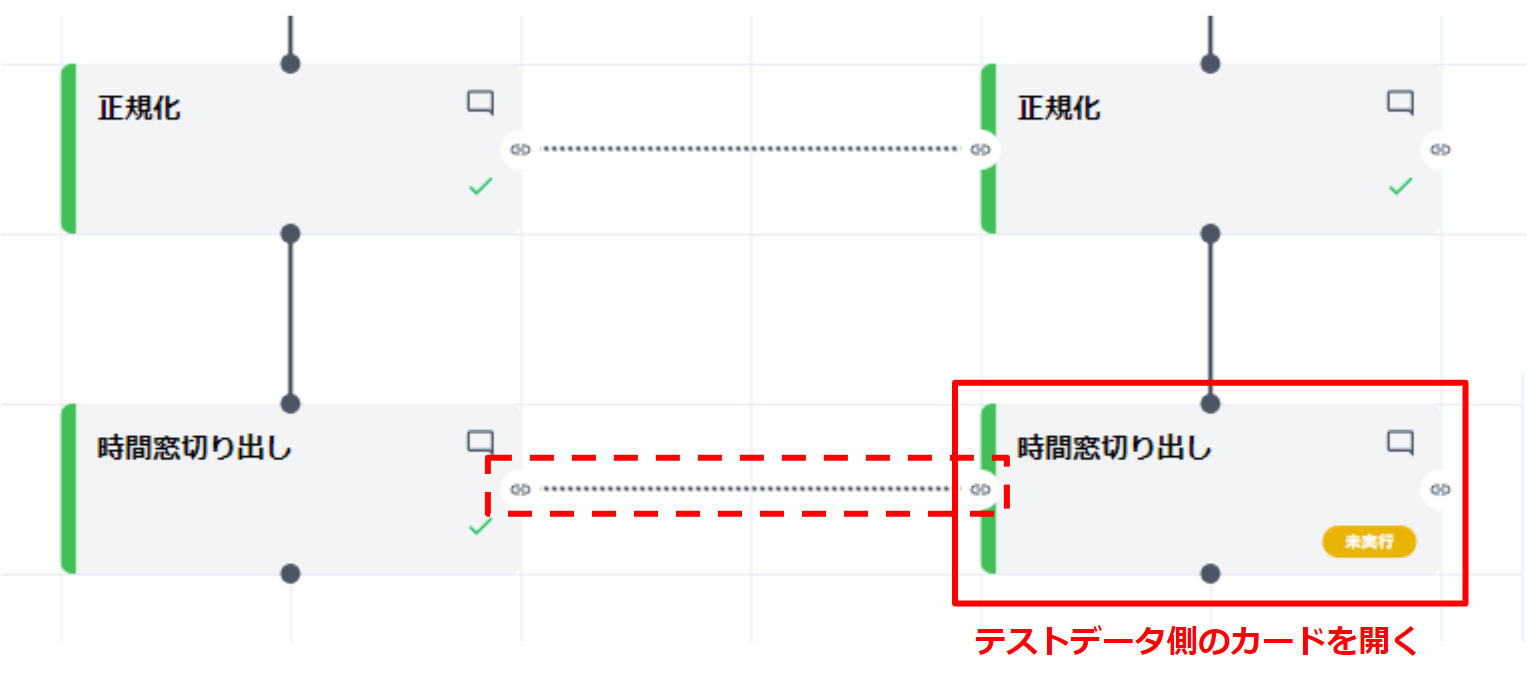
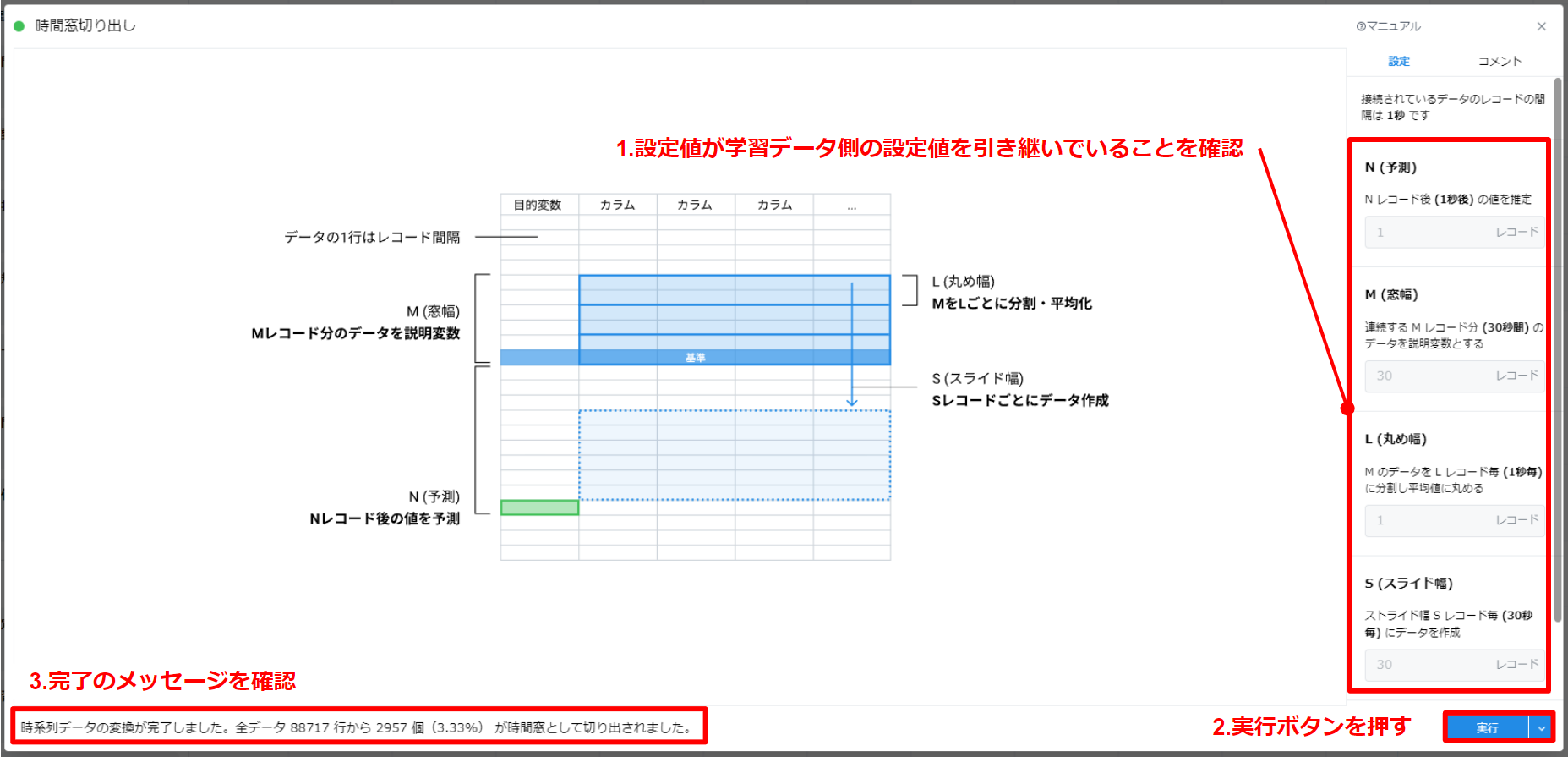
- テストデータのカードを開くと、“設定” パネルからコンフィグリンクで共有された各項目の値が確認できます。
- “実行” ボタンを押して処理を実行しておきます。
- 処理が完了するとステータスが表示されます。