4.2. 学習 #
4.2.1. 機能概要 #
- AI モデルの学習を行います。
利用する際の注意事項
- Informer の学習を行う場合は、 学習(Informer) を参照してください。
4.2.2. 入力と出力 #
| 種別 |
|---|
| 設計済み AI モデル |
| 時間窓切り出し実行後データ |
| 種別 |
|---|
| AI モデル |
4.2.3. 操作方法 #
4.2.3.1. 結線 #
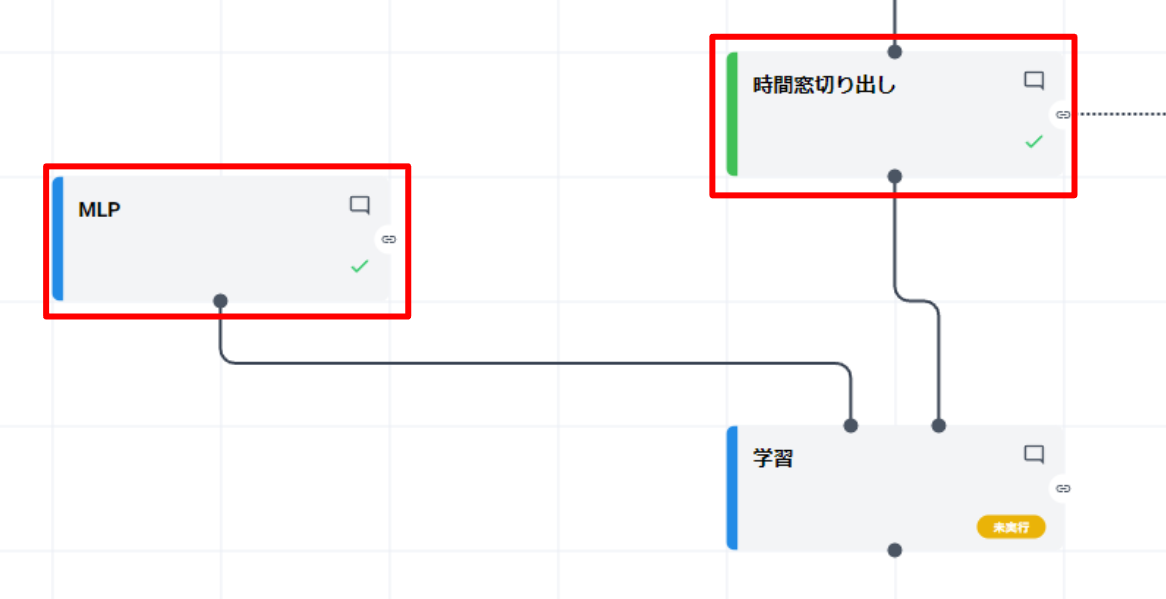
設計した AI モデル( MLP、 LightGBM など)と、学習用の 時間窓切り出し 後のデータを結線してください。
4.2.3.2. パラメータの設定 #
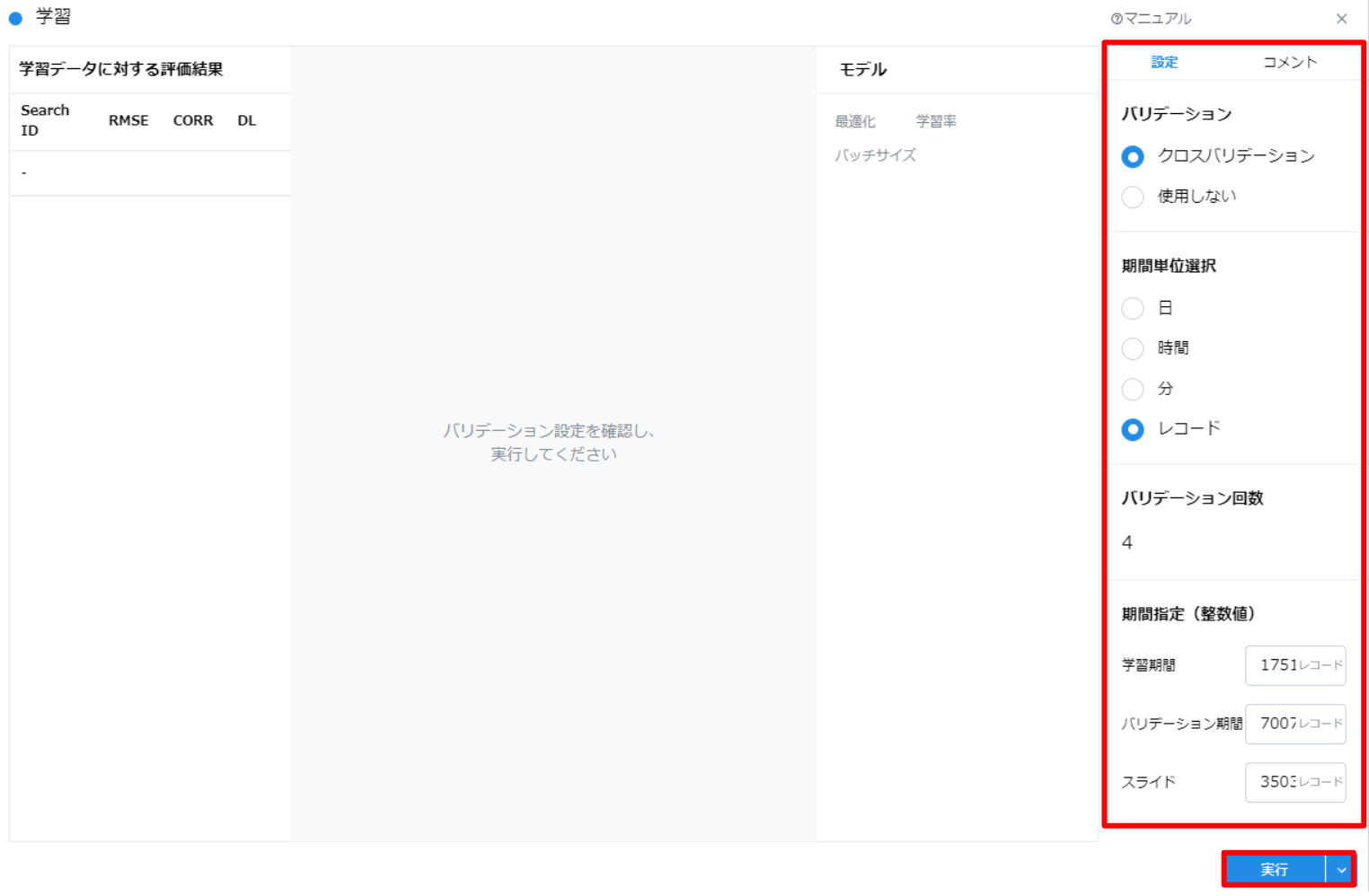
バリデーション
ハイパーパラメータの探索する場合は walk-forward validation の利用が必要です。
walk-forward validation とは、時間窓で切り出した複数のデータをそれぞれ学習データと評価データに分けて AI モデルの性能を確かめる時系列データに適したクロスバリデーションです。
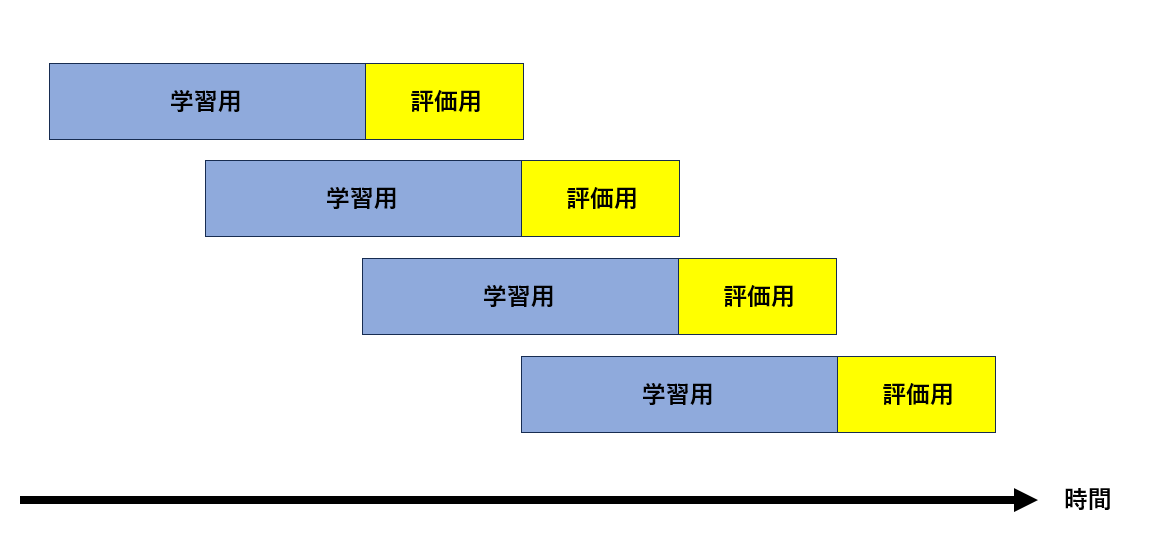
リークに関する詳しい説明やクロスバリデーション以外で発生するリークの例は こちらを参照してください。クロスバリデーションとは、モデルの性能評価やハイパーパラメータのチューニングに用いられる重要な手法の 1 つです。クロスバリデーションには様々な方法が知られていますが、Node-AI で扱うような時系列データには walk-forward validation というクロスバリデーションなどが適しています。
時系列データでは時間軸が非常に重要です。時系列データの予測では、評価データより未来の情報を用いて AI モデルを学習することは基本的に厳禁です。これは、未来の情報が学習データに “漏れる” と表現することから “リーク” と呼ばれます。リークが発生しないように、walk-forward validation では下図のように学習データと評価データを分割し、時間軸に沿ってモデルの性能を複数回チェックします。
| 設定 | 説明 | 条件 |
|---|---|---|
| walk-forward validation | walk-forward validation を利用する | |
| バリデーションしない | walk-forward validation を利用しない |
期間単位選択
“walk-forward validation"を選択した場合に表示されます。
| 設定 | 説明 | 条件 |
|---|---|---|
| 日/時間/分/レコード | バリデーション期間の単位 |
期間指定
“walk-forward validation"を選択した場合に表示されます。
| 設定 | 説明 | 条件 |
|---|---|---|
| 学習期間 | validation set の学習期間 | 正の整数 |
| バリデーション期間 | validation set のバリデーション期間 | 正の整数 |
| ストライド | validation set 作成時のストライド幅 | 正の整数 |
4.2.3.3. 実行 #
- “実行” ボタンを押すと、パラメーターに従い学習処理が行われます。
- 探索を中止する場合は"終了"ボタンを押してください。(MLP の設定でベイズ最適化かランダムサーチを選択した場合のみ)
- その時点で最も良いパラメータを用い、全期間のデータを用いた学習が実施されます。
- 学習を中止する場合は"中断"ボタンを押してください。
- 全ての学習処理は中止されます。
- 処理時間が 24 時間を超えるとタイムアウトし、処理が強制終了されます。
walk-forward validation を利用しない時
学習データの全期間のデータを用いて、学習が行われます。
walk-forward validation を利用する時
各 Validation set に対して、学習とテストが行われます。
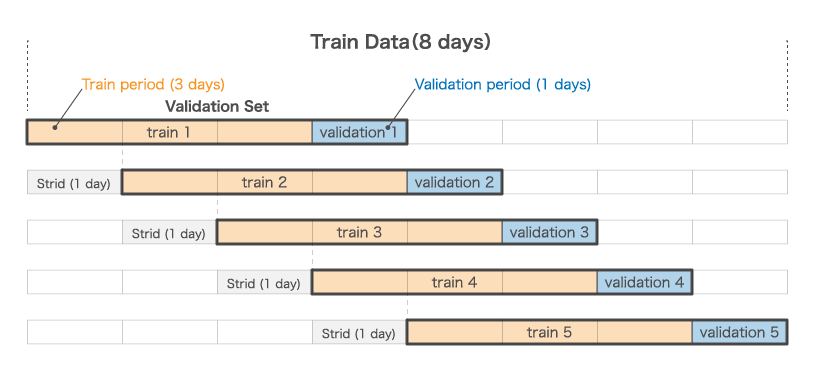
validation set の作成例
例として、8 日分の学習データを学習期間=3 日, バリデーション期間=1 日, ストライド=1 日 として、validation set を作成した場合、下記の通り、5 つの validation set が作成されます。
時刻が欠落している場合の walk-forward validation
時刻が欠落している場合にはその期間を避けて Train Period が作成されます。例えば、8 日分のデータのうち 2 日目のデータが存在しない場合、2 日目は避けて 3 日目のデータを使用した学習期間が作成されます。この時、1 つの学習期間に含まれる期間の長さは一定になります。
validation set に対する学習が行われている例
Train loss と Validation loss の表示について
Train loss と Validation loss のグラフは、AI モデルを MLP にした場合にのみ表示されます。
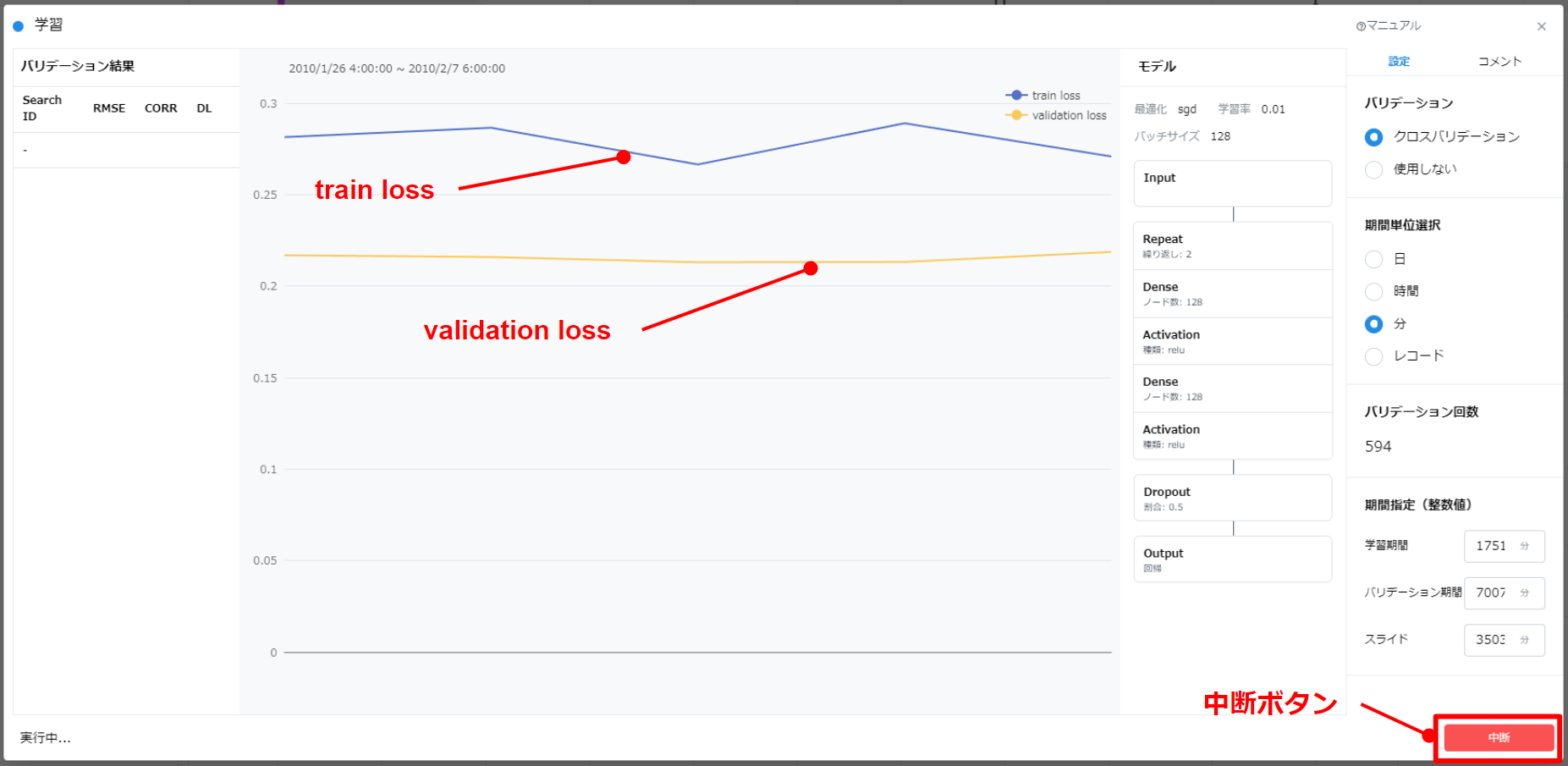
Train loss(青色)と Validation loss(緑色)が表示されます。
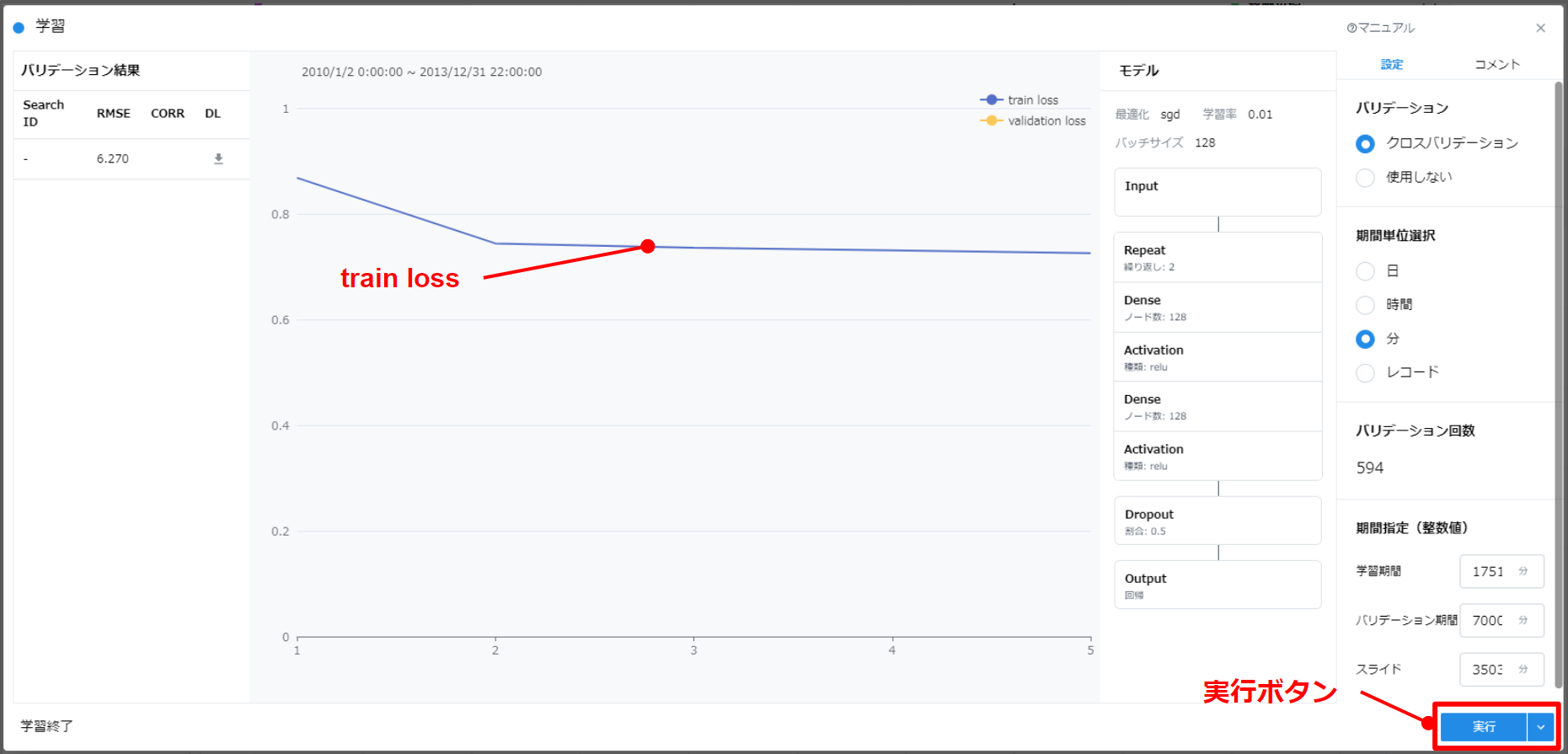
- 全ての Validation set に対する評価が行われた後、学習データの全期間のデータを用いて、学習が行われます。
- 全期間のデータを用いて学習する際は、Train loss(青色)のみ表示されます。
4.2.3.4. 学習結果の確認 #
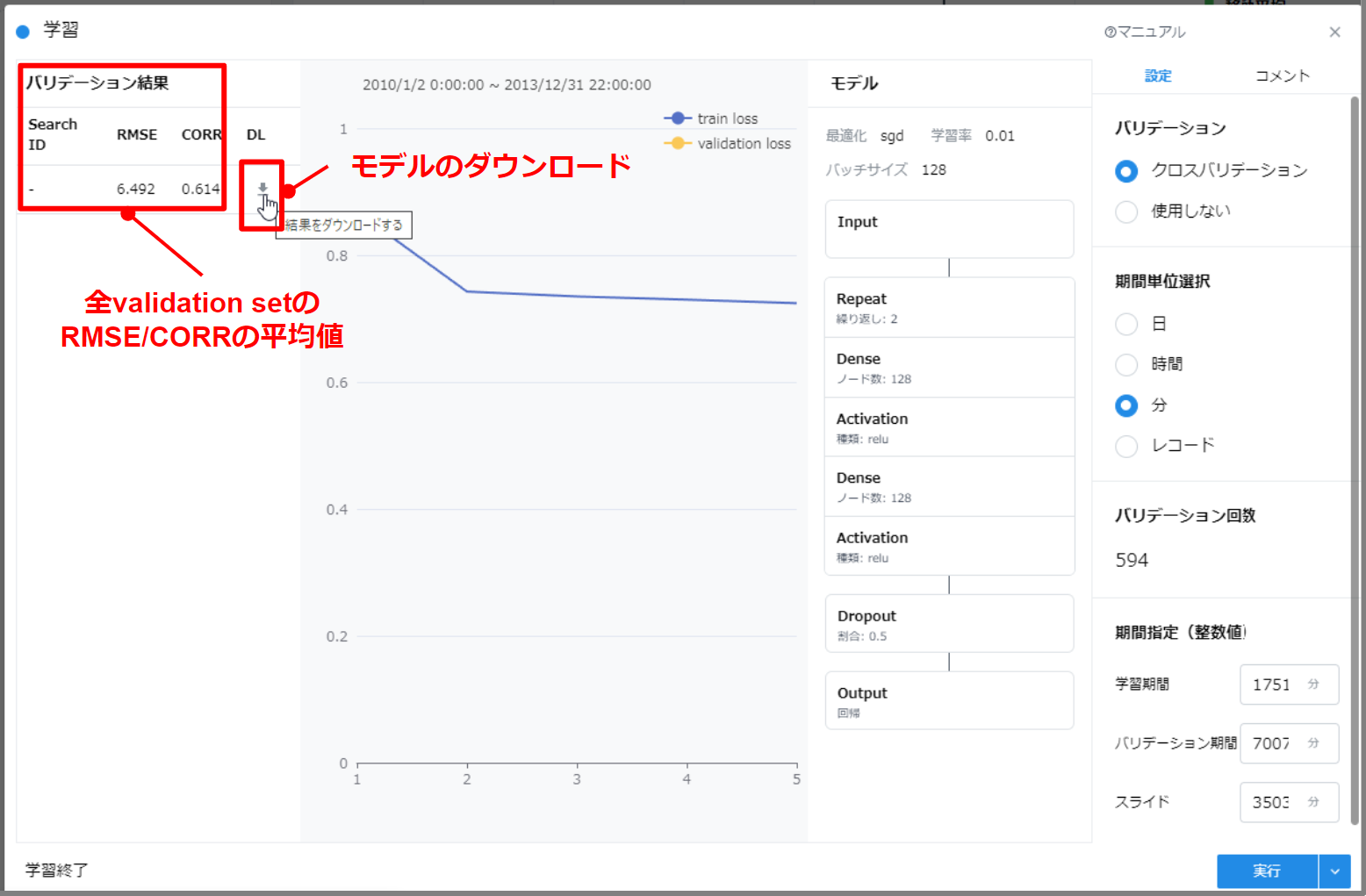
- 全ての validation set に対する評価指標(図の例では RMSE と CORR)の平均が validation tab に表示されます。
- これらの指標を見て、モデルの良し悪しを評価できます。
- あるいは、要因分析(Attribution Analysis)カードの結果等も踏まえてモデルの良し悪しを判断する場合もあります。
4.2.3.5. AI モデルのダウンロードと推論 API #
- 探索されたパラメータを用いて学習したモデルと、各種メタデータを zip ファイルでダウンロードできます。
- ダウンロードしたファイルは 推論 API で使用することができます。