リーク #
リークとは #
機械学習分野におけるリークとは “漏れる” を意味し、AIモデルを学習するときには本来得られるはずのないデータを使用することです。リークは分析者の意図に関わらず発生する可能性があるので注意が必要です。
リークが発生している状態で分析を進めると、手元のデータではAIモデルの精度が実際よりも良く見え、本番のデータではAIモデルが使い物にならないくらいに精度が下がることがあります。そのため、ビジネスの場面において誤った意思決定につながる可能性があります。また、分析しようとしているデータの蓄積方法やドメイン知識の有無によってはリークの発見が困難になる場合があります。
リークは、分析者の意図しないものなので発見が困難になる場合が多いです。ですが、扱うデータの理解、処理の仕組みや流れの理解を深めることでリークは未然に防ぐことが可能です。また、ドメイン知識と分析結果を照らし合わせ、直感に反して高い精度が出た場合はリークが発生している場合があります。このような場合「学習データ以外から得られた統計量を用いていないか」「不確定要素を含むデータを扱っていないか」「時系列を無視していないか」「適切でないクロスバリデーションを用いていないか」などのリークを疑い、データや処理内容を見直すことが大切です。
リークの具体例 #
リークが発生している可能性が高い例として以下の2つがあげられます。
データ分割前の正規化、データ分割後の評価データの統計量を用いた正規化 #
データを分割する前に計算した統計量(平均値や標準偏差)を使用して、分割後の学習データを正規化することはリークが発生している可能性が高いです。学習時には本来得られるはずのない評価データを用いて統計量が計算されているためです。
また、仮に正規化をデータ分割の後に行っていたとしても、評価データから得られる統計量を使って正規化をするのもリークに該当します。本来評価されるべき「未知のデータに対する予測性能」が正確に測れなくなるためです。
正しくは、分割したあとの学習データから得られる統計量のみを用いて評価データの正規化を行う必要があります。
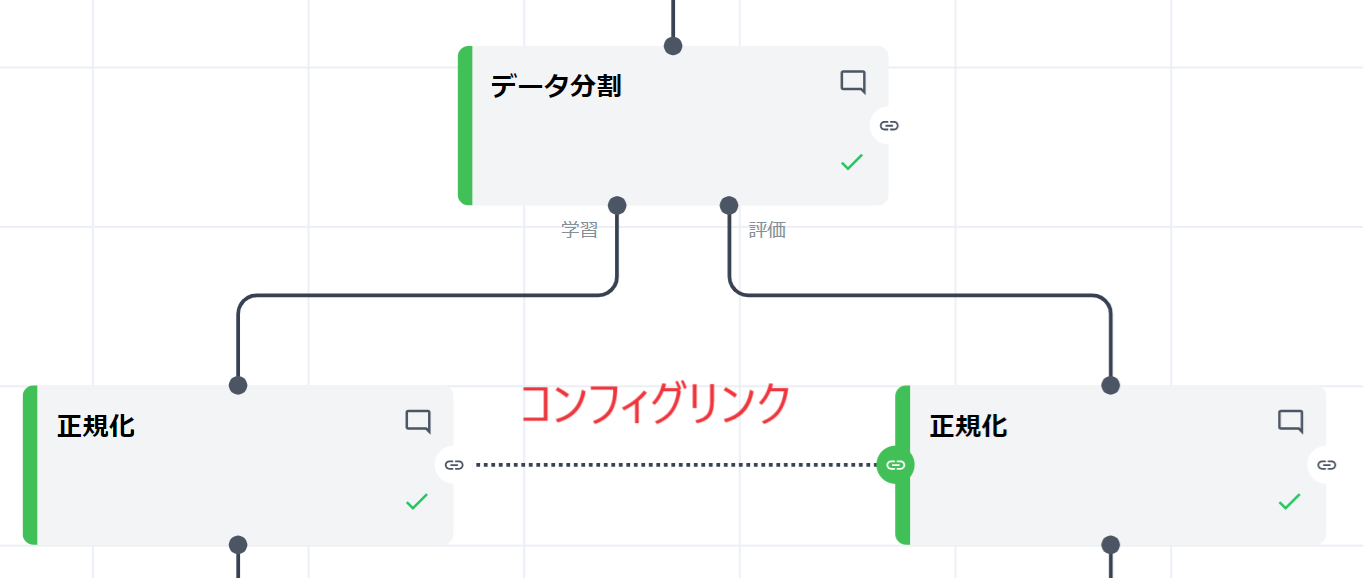
Node-AI における対処法(コンフィグリンクの活用)
Node-AIにおいては、コンフィグリンクを用いることで、リークを予防することができます。
コンフィグリンクとはカードを横方向に接続する線であり、カードの設定値を同種のカードに共有することができます。下の図の例では、2つの正規化カードの間にコンフィグリンクを接続することで、左側のカードから得られる統計量を右側のカードに受け渡し、右側でもそれらを使って正規化を行えるという意味になります。
予測時点では得られないデータを用いた予測 #
例えば、ある銘柄の株価の終値を予測するとき、別の銘柄の株価の終値の情報を含むデータを使用してAIモデルを作成することはリークが発生している可能性が高いです。知りたい銘柄の株価の終値を予測するとき、別の銘柄の株価の終値もまだ確定していないためです。正しくは、予測したい未来において確定していない事象を含むデータは削除してAIモデルの学習を行います。
Node-AI における対処法(クロスバリデーションの活用)
Node-AIにおいては、時系列を考慮したクロスバリデーションが利用でき、一部のリークを未然に防ぐことができます( 4.2.3. 操作方法)。