クイックスタート #
※所要時間目安は約 10 分です。
クイックスタートではNode-AIがあらかじめ用意している公開データを使用するため、事前の準備は必要ありません。
1. クイックスタートから学べる事 #
クイックスタートから、以下を学ぶことができます。
- ノーコードAIモデル開発ツール Node-AI の操作方法を理解できます。
- Node-AI を用いて AI モデルを作成するための基本的な流れを理解できます。
- Node-AI を用いて前処理から AI モデルの作成、評価、予測までを実施できます。
分析題材はこちら
データ分析の問題設定 #
あなたはシェアサイクルの運営企業の社員です。 自転車の整備などの都合から、自転車の需要を直感的に予測していました。
しかし店舗拡大や自身の引退を見据えて、温度や湿度、過去の利用状況を用いて未来の総利用台数(需要)を予測する AI モデルを作りたいと考えています。
具体的には、需要予測によって次のような効果が期待できます。
リソース最適化
需要予測は、特定の地域や時間帯において自転車がどれだけ利用されるかを正確に見積もることができます。これにより、必要なリソース(自転車の数や配置)を最適化し、適切な場所に十分な数の自転車を提供することが可能です。
サービス品質向上
正確な需要予測は、ユーザーが自転車を必要とする時点で適切な数の自転車を用意できることを意味します。これにより、ユーザーエクスペリエンスが向上し、サービス品質が維持されます。
コスト削減
過去の利用データや気象条件を考慮した需要予測により、不必要な自転車の配置や保管にかかるコストを削減できます。効果的なリソース利用は企業の運営コストを最小限に抑える助けとなります。
事業戦略の改善
正確な需要予測は将来の需要パターンを理解し、事業戦略を検討する上で重要です。将来の需要を予測することで、新しい店舗の設置やサービスの拡充などの戦略的な判断がより合理的に行えます。
顧客獲得と維持
需要予測が正確であれば、ユーザーがサービスを利用できない不便さを減少させ、顧客の獲得と維持に寄与します。ユーザーがいつでも利用可能なサービスを提供することは、競争優位性の向上にも繋がります。
2. 手順 #
アカウント作成後に表示されるチーム(トレーニングチーム)に、自動的に作成れるチュートリアル用のプロジェクト・キャンバスを使用します。
チーム、プロジェクト、キャンバスの説明については 1.1. チーム・プロジェクト・キャンバスについて をご参照ください。
2-1. キャンバスへのアクセス #
トレーニングチームには自動的に『チュートリアルプロジェクト』と事前にカードと説明を配置したいくつかの『練習用のキャンバス』が追加されています。
まずは、チュートリアルプロジェクトの中にある"Node-AIクイックスタート!5分で需要予測AIを開発"をクリックしてキャンバスを開いてください。
2-2. データの準備 #
学習に用いる目的変数・説明変数を選択し、データを準備します。
2-2-1. データカードの詳細画面を開く #
開いたキャンバスのもっとも上にあるデータカードをダブルクリックします。
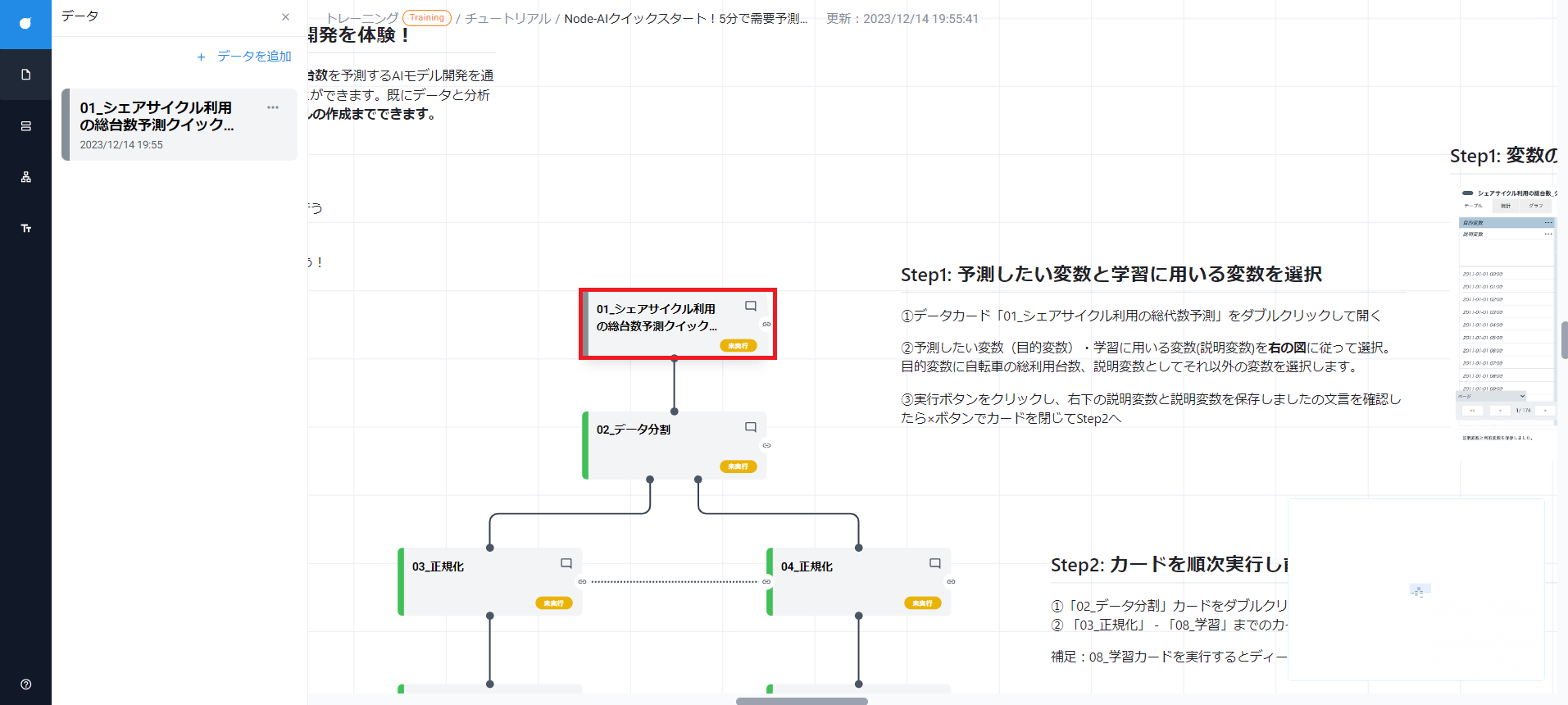
カードの詳細画面が表示されます。
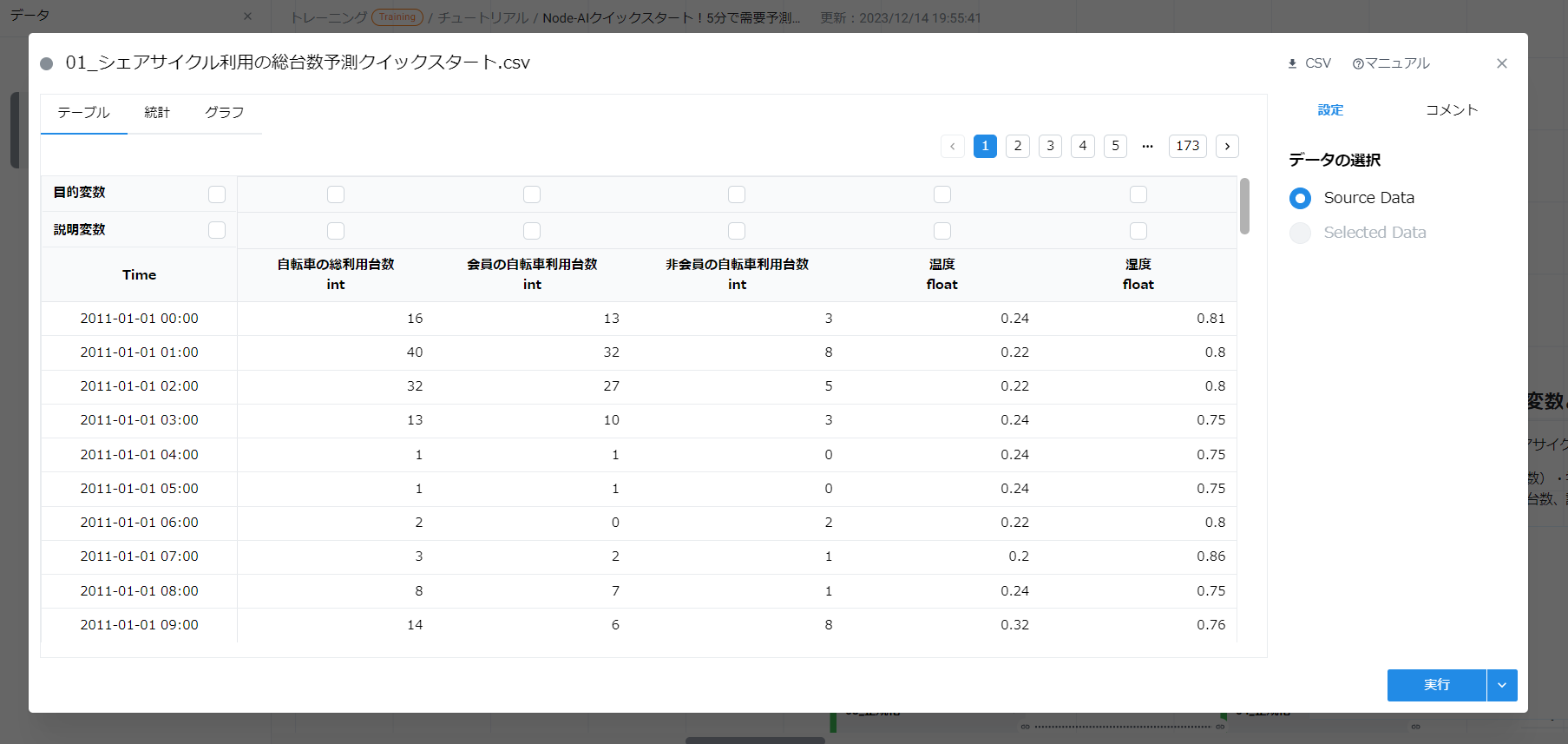
2-2-2. 目的変数・説明変数を保存する #
“目的変数” は予測する対象、“説明変数” はAIへの入力の対象となります。
今回は “自転車の総利用台数” を他データから予測するので、以下のように設定します。
(参考:
3.2. データ確認/説明変数・目的変数の設定)
- “目的変数” に “自転車の総利用台数” を選択します(初期状態で選択されています)。
- “説明変数” は “自転車の総利用台数” を除くすべての項目を選択します。
変数の一括選択
説明変数は一括で選択することができます。説明変数の横にあるチェックボックスをチェックすると、すべての変数にチェックが入ります。
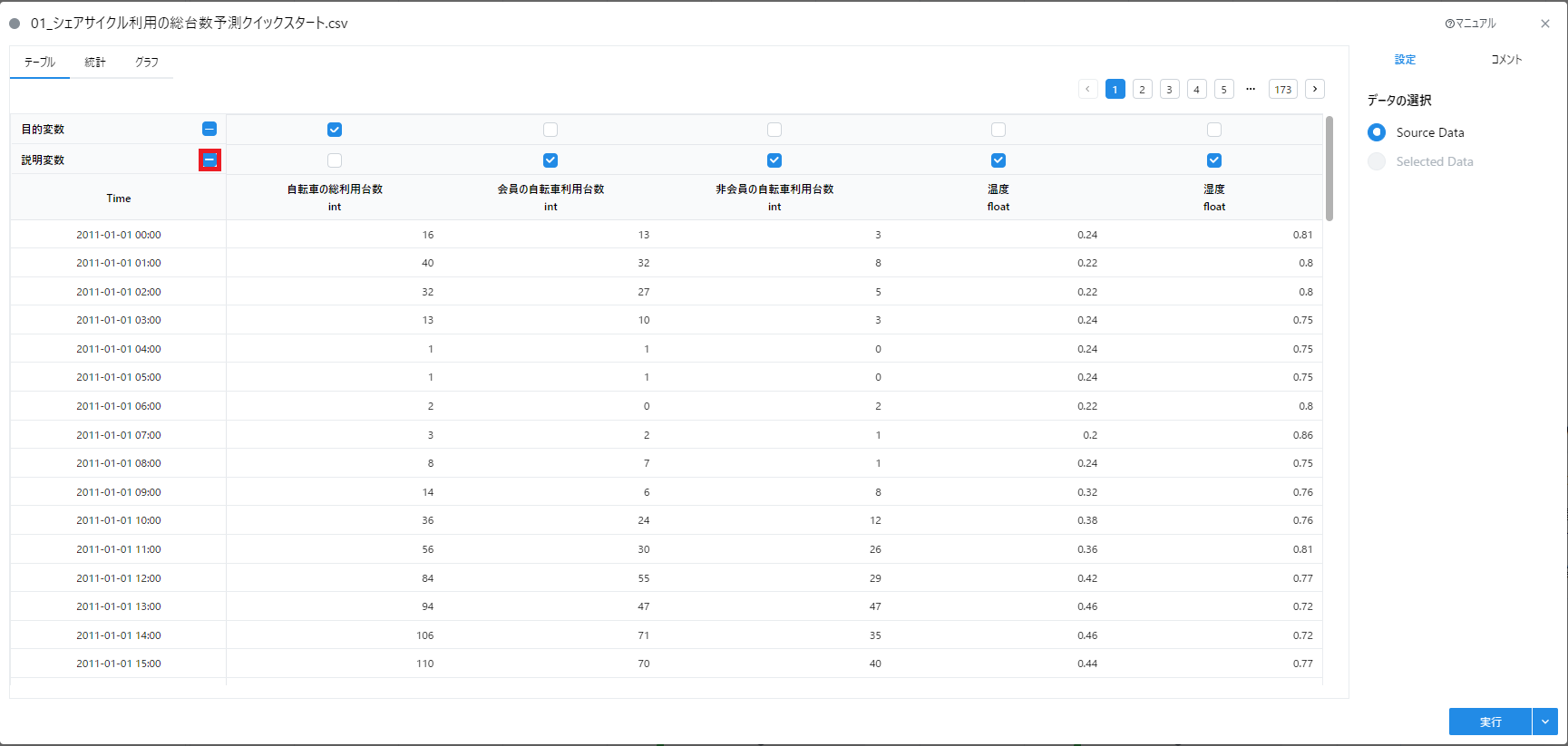
- “実行” ボタンを押して設定を保存します。実行完了後に「説明変数と目的変数を保存しました」とカード下部に表示されます。
- カードの詳細を右上の×ボタンか、カード外をクリックすることで閉じます。
2-3. ツリー実行 #
2-2. でデータカードが用意できました。
次はデータを分析するためのカードを実行します。
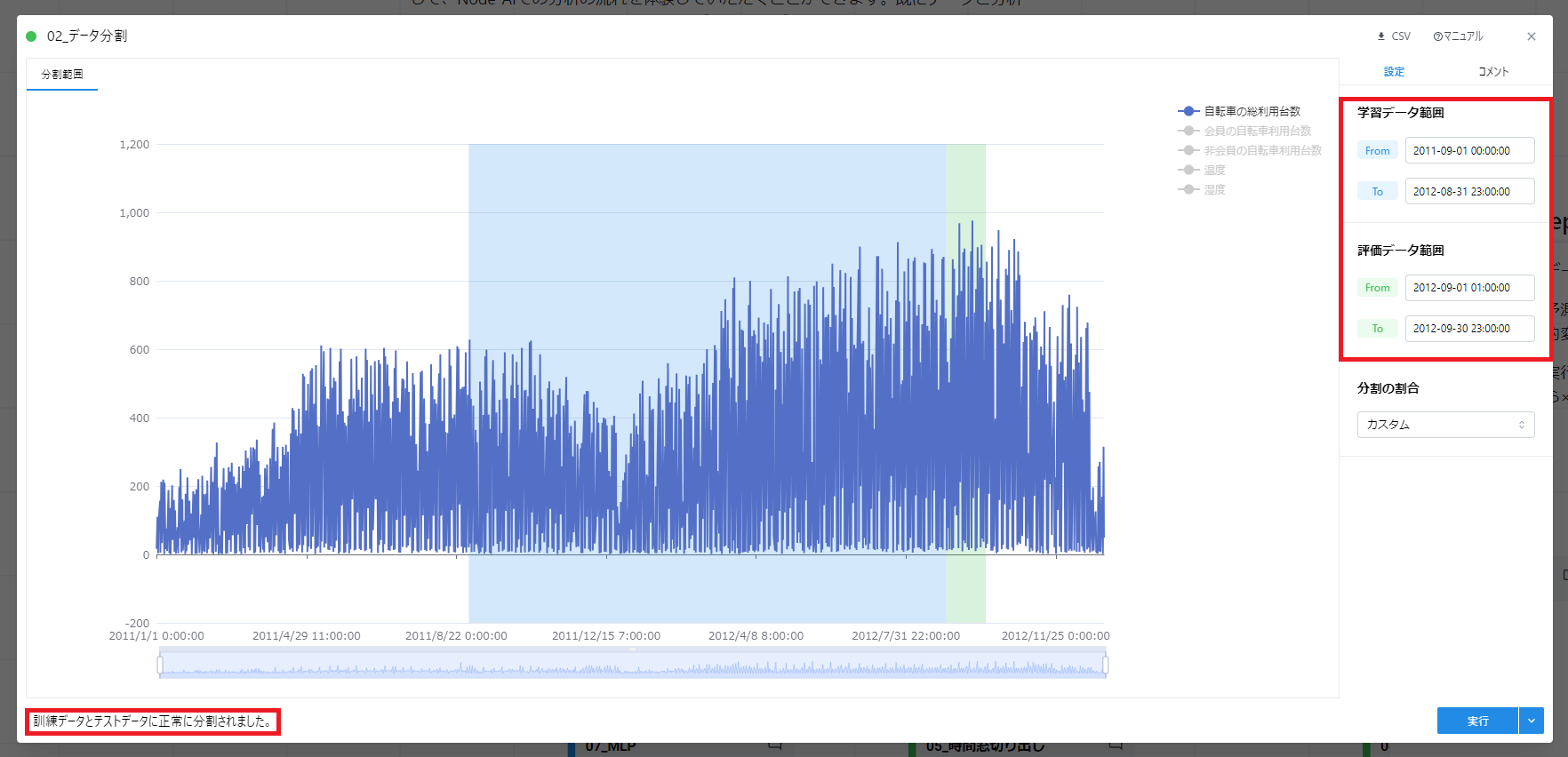
まずは、データ分割を実行します。
- データ分割カードをダブルクリックで開き、学習・評価データの期間が設定されていることを確認します。
- データ分割を「実行」します。メッセージ「訓練データとテストデータに正常に分割されました。」がでることを確認してください。
同じ要領で、学習をするのに必要な正規化・時間窓切り出し・MLP・学習の順でカードを実行していきます。
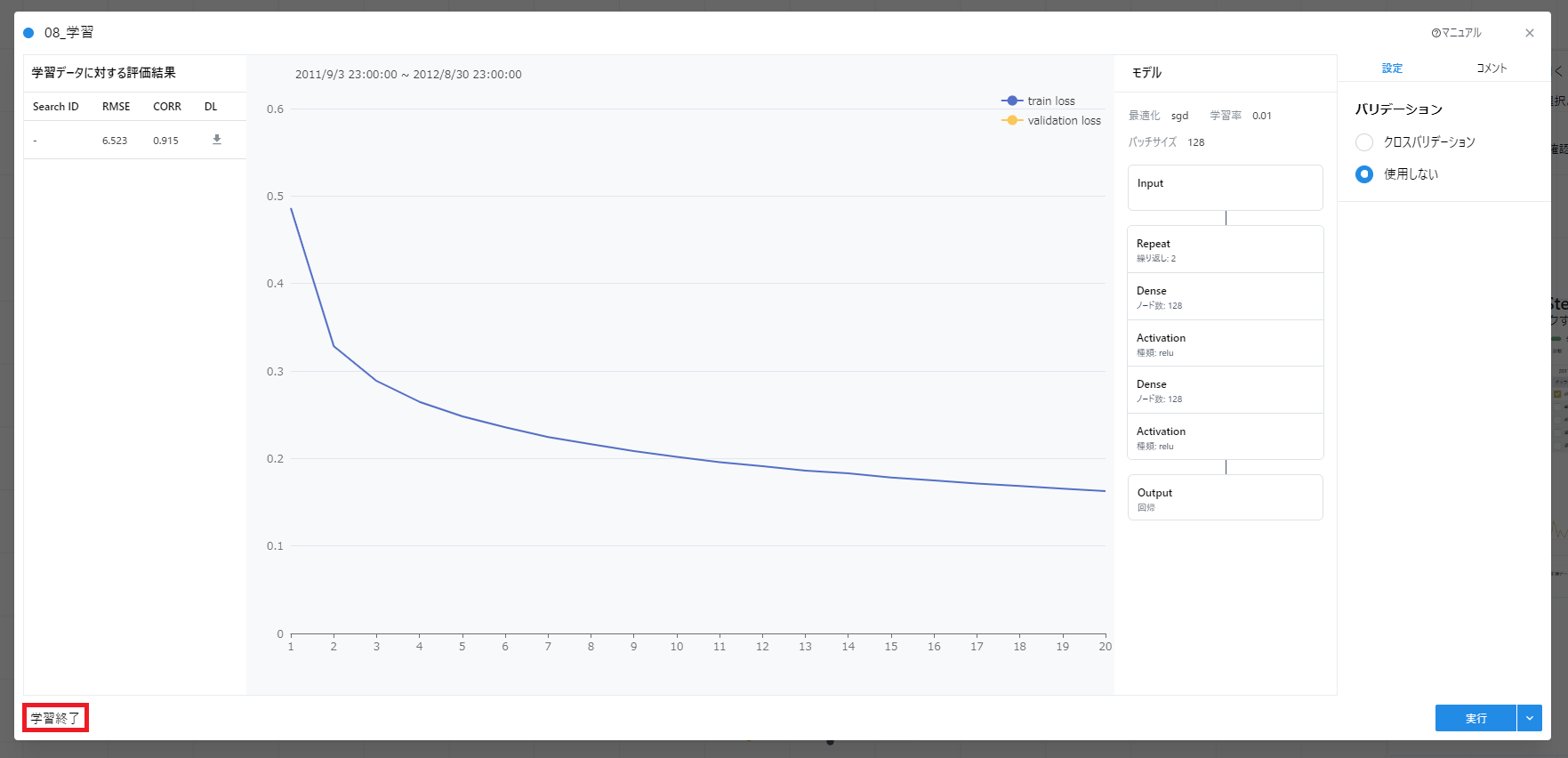
学習が実行し終わった段階でAIモデルが作成されます。
詳細はこちら
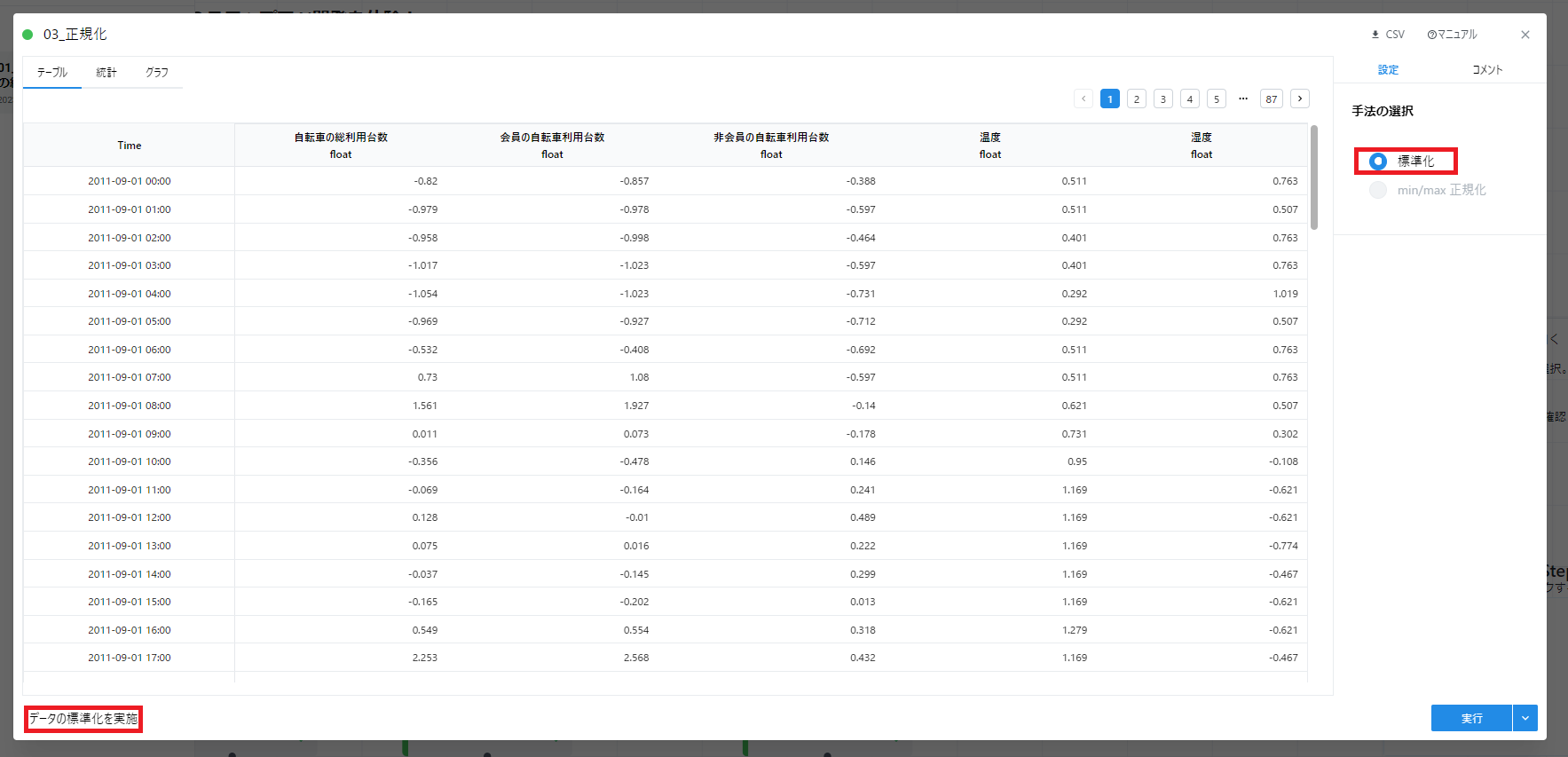
- データ分割の学習側から結線されている正規化カードを開き、下記のように初期値として標準化が選択されていることを確認し、実行します。
(参考: 1.6. 正規化)
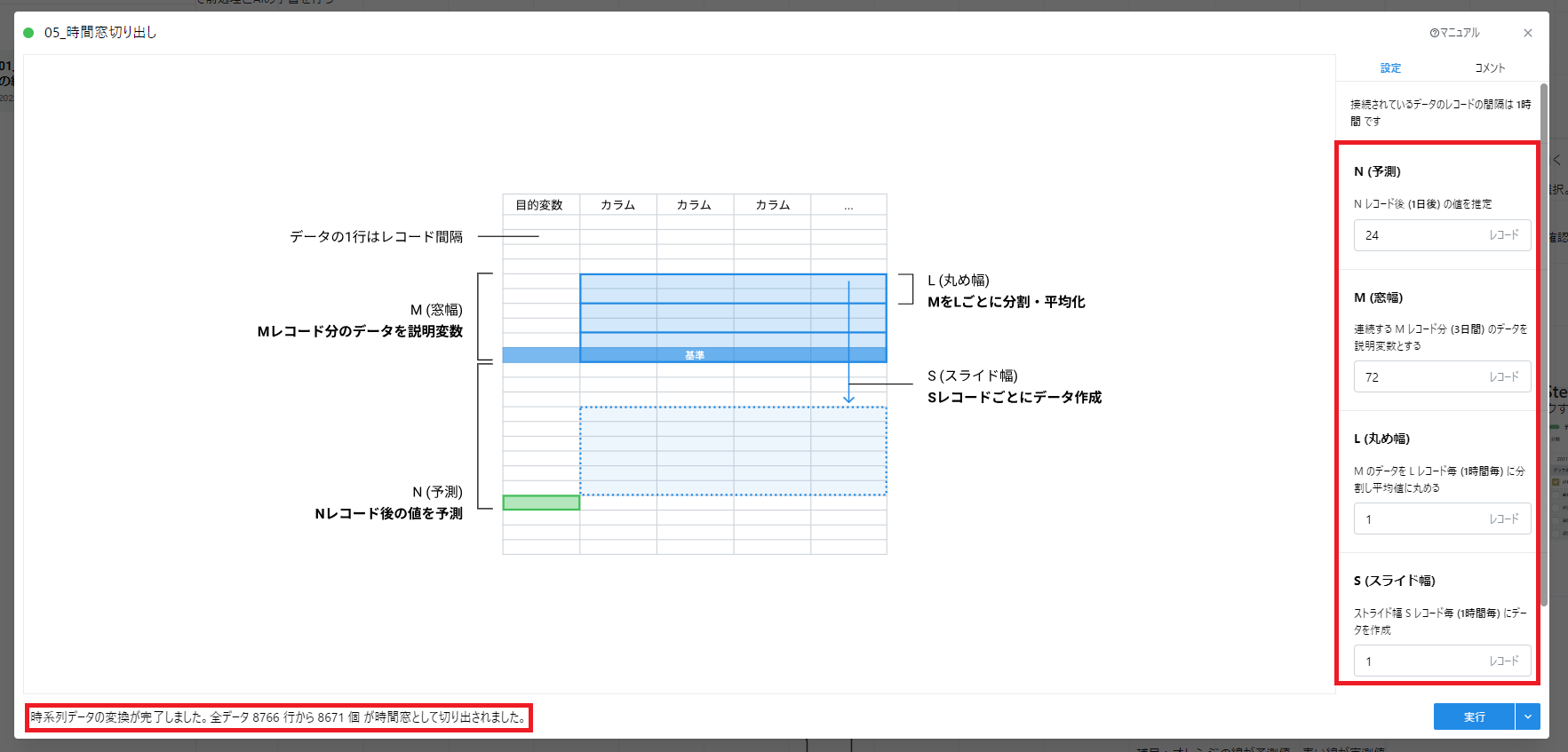
(参考: 3.2. 時間窓切り出し)
- N: 予測先 = 24
- M: 窓幅 = 72
- L: 丸め幅 = 1
- S: ストライド幅 = 1
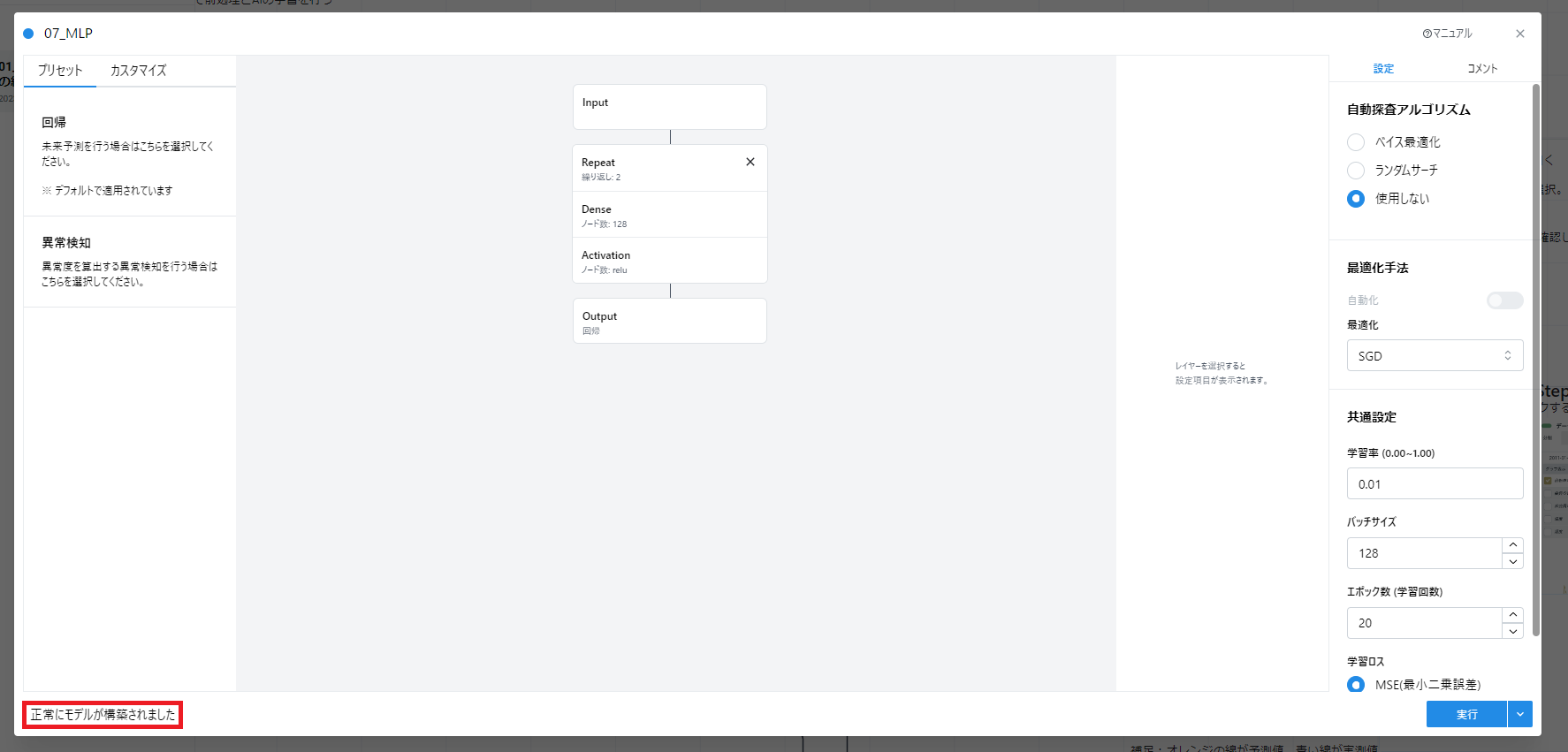
- MLPカードを開き、モデルと設定値を見てそのまま実行します。
本来はモデル構造やパラメータの値を調整し、精度の高いモデルを作ることが目的となります。
ただし初期値でも学習は行えるため、今回は初期設定のままで実行しています。
(参考: 4.1.a. 深層学習モデルの設計 (MLP))
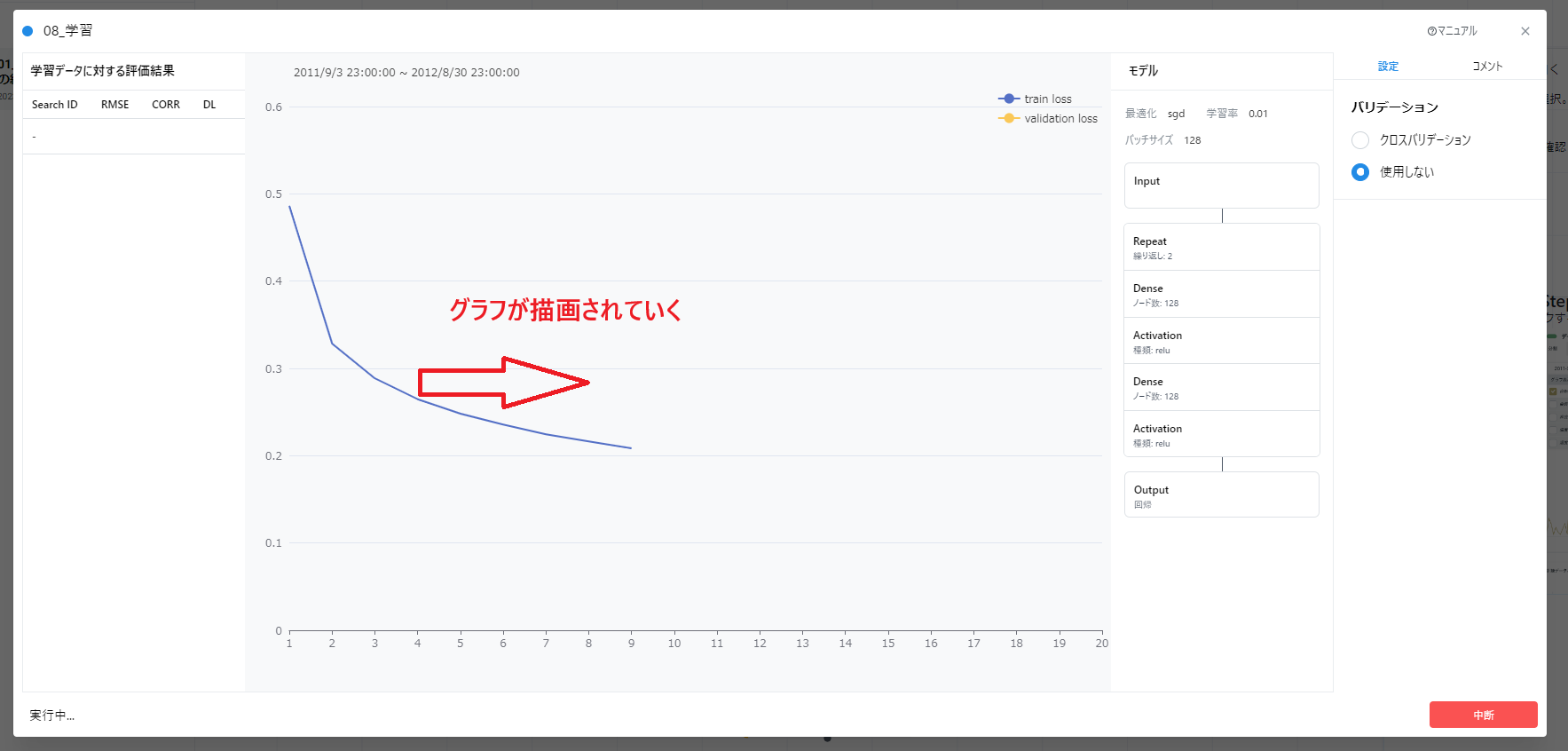
- 学習カードを開き、下記のように「バリデーションしない」が選択されていることを確認し、実行します。
実行が進むとともに学習結果のグラフが随時更新されていくのが確認できます。
(参考: 4.2. 学習)
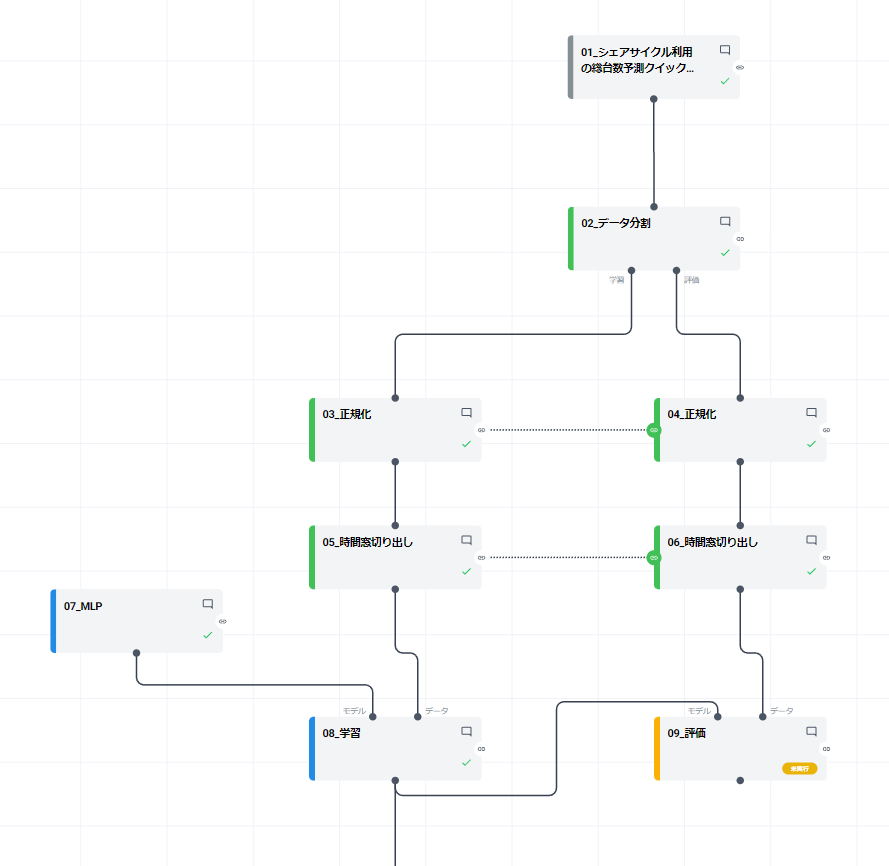
ここまでの手順でキャンバスは以下の状態になっています。 ご確認ください。
これでAIモデルが作成できました。
2-4. 評価カード実行 #
2-3. で作成したAIモデルを評価します。 示されている順番に従って、前処理カードを実行したのち、一番下にある評価カードを実行してください。
詳細はこちら
学習側のカードから評価側のカードに伸びているコンフィグリンクが確認できます。
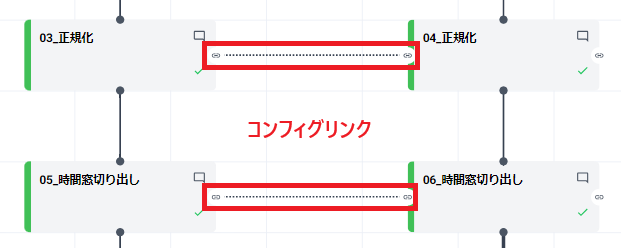
これは繋ぎ元のカードの設定を繋げ先のカードに持たせる機能があります。
学習側で実行したカードと同様の設定値が既に設定されているので、評価側のカードは実行するだけで学習側と同等の処理が行えます。
- データ分割の評価側から結線されている正規化カードを開き、実行します。
- データ分割の評価側から結線されている時間窓切り出しカードを開き、実行します。
- 評価カードを開き、実行します。
(参考: 5.1. 評価)
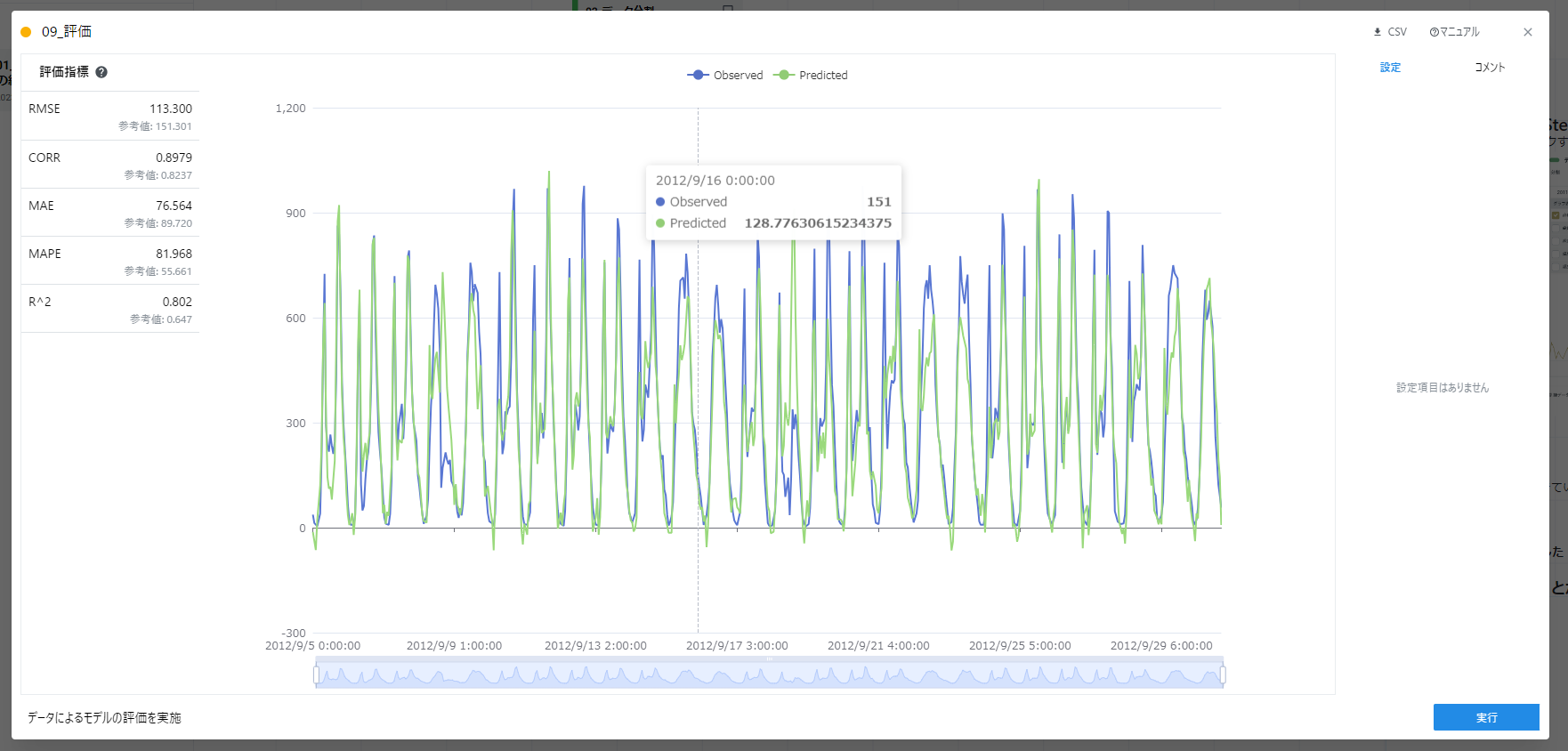
評価カードの実行が終わると以下のようなグラフが表示されます。
各評価指標の詳細
各評価指標の説明
指標 説明 RMSE(Root Mean Squared Error/二乗平均平方根誤差) 予測値と実測値の誤差を二乗し、それらの平均を取った後、平方根を求めることで算出される指標です。RMSEは、予測誤差の大きさを考慮し、外れ値の影響を強調する特徴があります。モデルの予測精度を評価する際によく用いられ、値が小さいほど予測精度が高いとされます。 CORR(Correlation Coefficient/ピアソンの相関係数) 予測値と実測値の間の直線的な関係の強さを示す指標で、-1から1の範囲の値を取ります。1に近い場合、正の相関が強く、予測値が増加すると実測値も増加することを示します。-1に近い場合、負の相関が強く、予測値が増加すると実測値は減少することを示します。0に近い場合、予測値と実測値の間にはほとんど相関がないことを示します。ピアソンの相関係数は、予測モデルの適合度を評価する際に参考にされることがあります。 MAE(Mean Absolute Error/平均絶対誤差) 予測値と実測値の絶対誤差の平均を表します。予測誤差の大きさを直感的に理解しやすい指標で、予測モデルの精度を評価する際に使用されます。 MAPE(Mean Absolute Percentage Error/平均絶対パーセント誤差) 予測値と実測値の絶対誤差を実測値で割り、その平均をパーセント表示したものです。予測誤差が実測値に対してどの程度の割合で発生しているかを示す指標で、予測モデルの相対的な精度を評価する際に用いられます。 R^2(Coefficient of Determination/決定係数) 予測モデルが実測値をどの程度説明できるかを示す指標で、0から1の範囲の値を取ります。1に近いほど予測モデルが実測値をよく説明していると言え、モデルの適合度を評価する際に使用されます。R^2は、予測値と実測値の相関関係の強さを示すピアソンの相関係数を二乗したものです。
評価の見方(参考)
R2(決定係数)とMAE(平均絶対誤差)に注目すると、R2は参考値より大きく、MAEは小さくなっていることが確認できます。
- R2は予測値と実測値の当てはまり具合を表し、1に近いほど予測値が実測値に当てはまっていることを意味しています。
- MAEは予測値と実測値の絶対値が平均的にどの程度の離れているかを表し、0に近いほど予測できていることを意味しています。
MAEは76.564となっており、予測値を参考に自転車の利用台数を求めると、平均し76台の誤差があることが把握できます。 このことから、76台多く利用されることを念頭に空き自転車を管理すると良いと考えられます。
また、参考値は未来予測するために用いる説明変数の時刻を使って評価指標を計算したもので、開発したモデルが有効か判断するための材料です。 参考値と比較すると、開発したAIモデルの方が高い精度で予測できていることが確認でき、十分に活用できるものだと判断できます。
2-5. 各カード実行(予測) #
モデルは評価までで終了ではなく、業務への活用のため、新しいデータに対して繰り返し未来予測を行う必要があります。 予測カードを使うことで、新しいデータへの前処理、予測を一気に行うことができます。
2-3. で作成したAIモデルを用いて将来データの予測を行います。
トレーニング用チームでは公開データから予測用のデータを選択できます。 FreeプランまたはBusinessプランではオリジナルのCSVデータをアップロードできます。
予測データの入力 #
- 他のカードと同様、予測カードをダブルクリックで開いてください。
- 予測に用いる公開データを選択してください。
- 今回は『シェアサイクル利用の総台数予測(クイックスタート用)』をチェックします。

- “実行” ボタンを押してください。
予測カードの実行が終わると以下のようなグラフが表示されます。
(参考: 6.1. 予測グラフの確認)
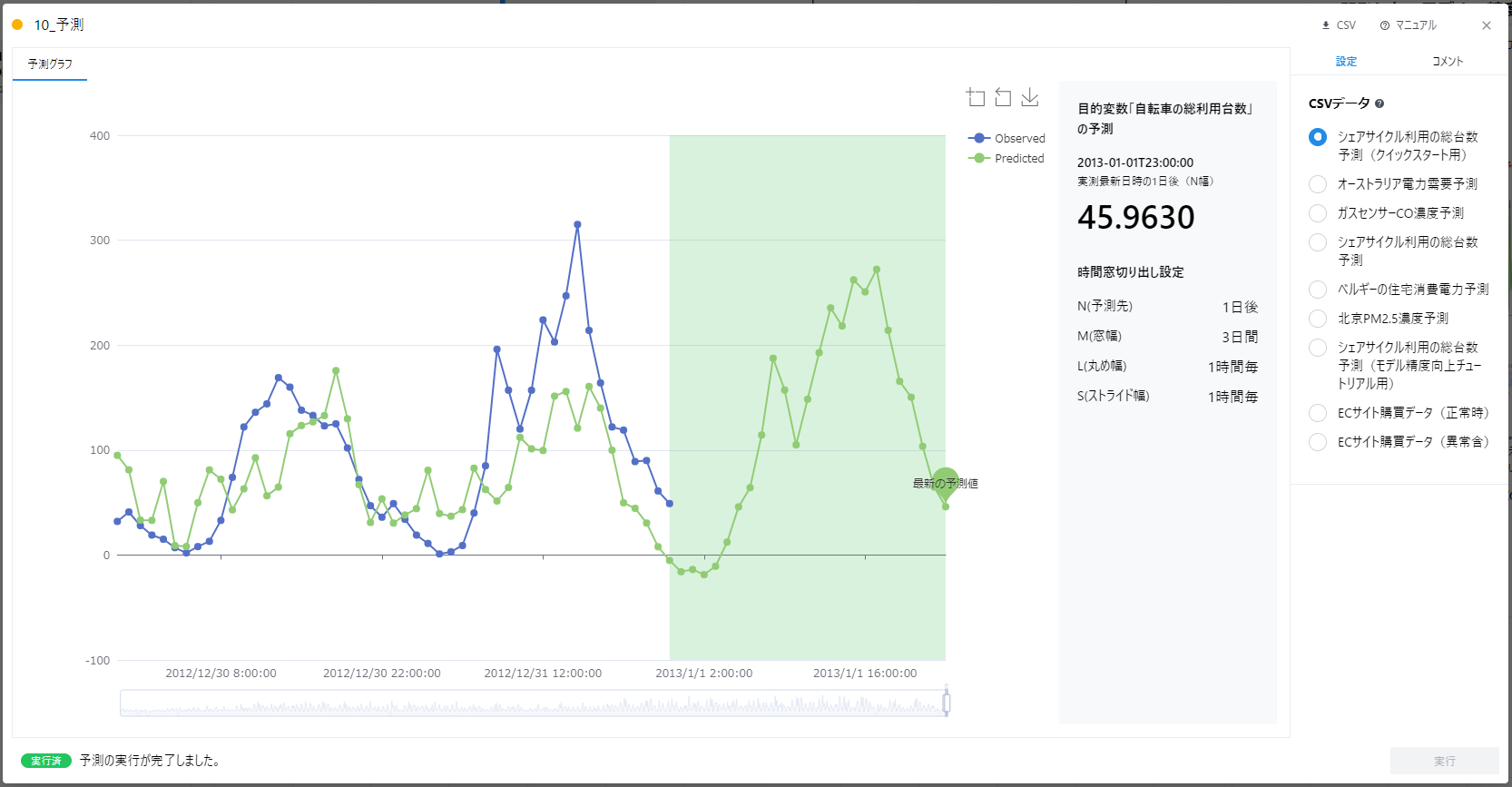
任意のデータに対する予測
Freeプラン、Bussinessプランでは自分で用意した任意のデータに対する予測ができます。Freeプラン、Bussinessプランでは予測カードを開き、CSVファイルをアップロードしてください。
3. 次のステップ #
このクイックスタートではNode-AIの基本的な概念や操作について説明しました。 さらに本格的な分析やビジネス利用を検討するには以下をご参照ください。
- 分析の流れをより深く理解し、Node-AIの特徴的な機能を体験する
- AIモデルの精度を向上させる方法を理解する
- 作成したAIモデルを活用し、推論アプリケーションを構築する