データの準備 #
このページでは、 Node-AI に入力するデータの形式や条件について説明します。
こちらの内容は Node-AI だけでなく、時系列データ分析を行う上で一般的に行われる内容を含みます。
時系列データ分析技術の学習としてもお役立てください。
プランによるアップロード方法の制限について
- アカウント作成後に用意される “トレーニング” チームでは公開データ以外のアップロード方法は利用できません。
- オリジナルのデータをアップロードするには新規のチームを作成し、FreeまたはBusinessプランをご利用ください。
プランの詳細は こちら
Node-AI で扱える時系列データの形式 #
Node-AI では、以下の条件を全て満たす時系列データを扱うことができます。
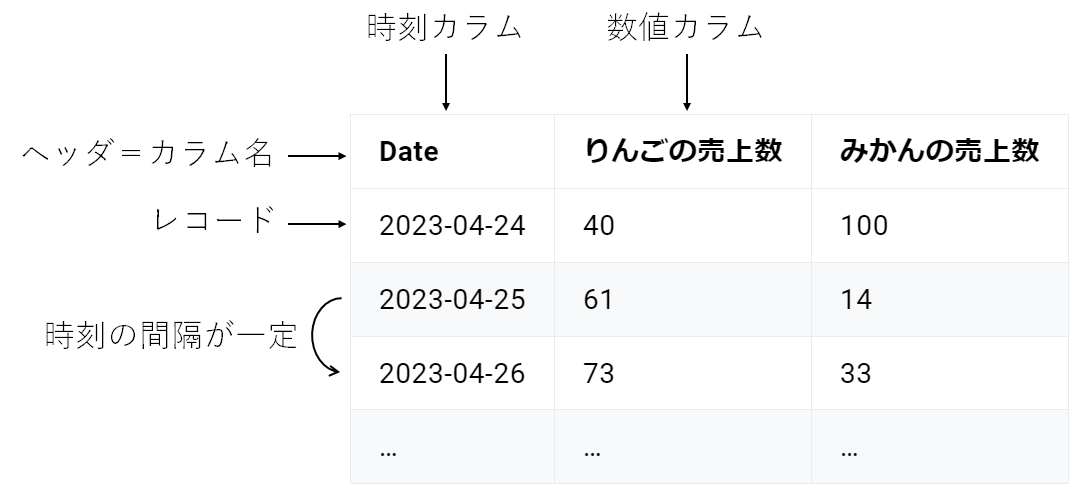
- CSV (Comma-Separated Values) 形式である
- 表計算ソフトなどの形式(例:xls)である場合はCSVファイルに変換してください。
- 1レコード目にヘッダとして カラム名 (列名)が格納されている
- ヘッダを除き、最低2レコードのデータが格納されている
- ただし、AIモデルの学習には現実的に数十~数百レコード以上のデータが必要とも言われています。
- 実際に必要なデータ量は解きたい問題設定、精度目標、データの傾向、使用するAIモデルの種別などに依存します。
- 1つの 時刻カラム と、 その時刻に紐づく数値データのカラム が最低1つ格納されている
- 時刻カラムの値は 時刻としてプログラムが識別可能(後述) である
- レコードの値は 全てのレコードで意味が同じである(後述) 。
- 時刻カラムの値に 重複 が存在せず、 間隔が一定 であり、昇順にソート されている
- 間隔が一定でない場合も リサンプリング などにより分析できることもあります。
データの具体例 #
以下は「りんごの売上数」と「みかんの売上数」を1日単位で記録した時系列データです。
上記の条件を全て満たしているため Node-AI で扱うことができます。
| Date | りんごの売上数 | みかんの売上数 |
|---|---|---|
| 2023-04-24 | 40 | 100 |
| 2023-04-25 | 61 | 14 |
| 2023-04-26 | 73 | 33 |
| … | … | … |
以下は「レコードの値は 全てのレコードで意味が同じである」という条件を満たしていないため、 Node-AI では扱うことができない時系列データ です。
例えば2レコード目と3レコード目は、それぞれX市とY市の人口を示すデータであり、レコードの値が示す意味が同じであるとは言えません。
| Year | 市 | 人口(万) |
|---|---|---|
| 2010 | X市 | 40 |
| 2010 | Y市 | 140 |
| 2011 | X市 | 41 |
| 2011 | Y市 | 139 |
| … | … | … |
その代わり、以下のようにX市とY市のカラムに分離することで条件を満たすことができます。
| Year | X市の人口(万) | Y市の人口(万) |
|---|---|---|
| 2010 | 40 | 140 |
| 2011 | 41 | 139 |
| … | … | … |
また、以下のようなクレジットカードの決済金額と不正利用フラグをデータにした場合はどうでしょうか。
| Date | 不正フラグ | 決済金額 | ユーザーID |
|---|---|---|---|
| 2020-05-23 11:22 | 0 | 1300 | AAA |
| 2020-05-24 10:10 | 1 | 52000 | BBB |
| 2020-05-25 21:43 | 0 | 250 | AAA |
| … | … | … | … |
これは「不正フラグを目的変数とした不正検知機械学習モデル用のデータ」と見なすこともできますが、 Node-AI では扱うことができないデータ です。
「時刻の間隔が一定である」という条件を満たしていないことや、レコードには「ユーザーID」が紐づいており「レコードの値は 全てのレコードで意味が同じである」データとは言えないためです。
代わりに以下のような形式であればNode-AIの分析対象となるデータとなります。
| Date | 不正合計数 |
|---|---|
| 2020-05-23 | 3 |
| 2020-05-24 | 10 |
| 2020-05-25 | 5 |
| … | … |
アップロードに失敗する可能性のあるファイル #
ここではよくあるデータのアップロード失敗の原因と、その解決方法について取り上げます。
1. データの中身が文字化けしている #
- 原因 : 日本語を含む CSV ファイルを表計算ソフトウェアで編集するとデータが文字化けする場合があります。文字化けすると CSV 形式の構造が壊れることがあるためデータのアップロードに失敗します。
- 解決方法 1 : カラム名などに日本語を含まないように事前に修正します。
- 解決方法 2 : 軽微な修正はテキストエディタなどテキストファイルとして編集できるソフトウェアを使って編集します。詳しくは こちらをご覧ください。
2. 時刻がプログラムが認識できない形式である #
-
原因 : データ内の時刻が特殊な形式で表記されているなどの場合にエラーが発生します。
-
解決方法 : 時刻のデータが適切なフォーマットになっていることを確認します。特に
2023年12月24日などのように日本語を含む時刻は取り扱えないケースがあります。 -
例 : 失敗:
2023/12/24_12:00成功:2023/12/24 12:00(日付と時刻の間にアンダースコア_が含まれているため時刻の変換に失敗します) -
Node-AI で扱える時刻形式の例
それぞれのパターンを組み合わせて使用できます。 ただし複数の形式を同じファイルに含めることはできません。
| 時刻形式 | 例 |
|---|---|
| yyyy-mm-dd | 2021-01-23 |
| yyyy/mm/dd HH:MM | 2021/01/23 11:22 |
| yyyy.mm.dd HH:MM:SS.fff z | 2021.01.23 11:22:33.000 UTC |
| yyyy-mm-ddTHH:MM:SSZ (ISO8601形式) | 2021-01-23T11:22:33Z |
| yyyymmddTHHMMSS±HHMM (ISO8601形式) | 20210123T112233+0900 |
※ yyyy: 年、mm: 月、dd: 日、HH: 時間、MM: 分、SS: 秒、fff: ミリ秒、z: タイムゾーン(“UTC” または “JST” に対応)
- Node-AI で 扱えない 時刻形式の例
| 時刻形式 | 例 | 理由 |
|---|---|---|
| yyyy年mm月dd日 | 2021年01月23日 | 日本語の形式は扱えません |
| dd/mm/yyyy | 23/01/2021 | 年-月-日の順序である必要があります |
| yy-mm-dd | 21/01/23 | 年は4桁である必要があります |
| unixtime | 1611327600 | Unix時間は対応していません |
4. 時系列データ以外の値が混入している #
- 原因 : データの集計結果や補足のテキストがファイルの末尾などに含まれている場合はエラーとなります。
- 解決方法 : 生データ以外のテキスト情報は事前に削除しておきます。
4. データが暗号化されている #
- 原因 : PC の設定により CSV ファイルが自動で暗号化されている場合があります。このような暗号化済みファイルを Node-AI では取り扱うことができません。
- 解決方法 : 暗号化ソフトを使って暗号化を解除します。
「きれいな」時系列データを用意する方法 #
Node-AI が期待するのは上記のような多くの条件をクリアした「きれいな」時系列データです。
しかし、業務等で利用されているデータは必ずしも最初からそのように整理されているわけではありません。
そこで、一般的にデータ分析の前に行われるデータ整形(データクレンジングとも言う)の例について紹介します。
ただし、ここでは SQL や Python などのプログラミング言語によるデータクレンジングの方法は記載しません。
また一部のクレンジングについては Node-AI の前処理機能で解決可能な場合があります。
1. 手作業 #
- 表計算ソフトには「CSV形式で保存する」機能が搭載されていることがあります。表計算ソフトのマニュアル等を確認してください。
- 表計算ソフトのデータは「シート」という概念で複数の表形式のデータに分離されていることがあります。1つのシートとなるようにデータをコピー&ペーストするか、不要なシートを削除をしてください。
2. 表計算ソフトの機能を使う #
- 「レコード間の値が一貫した関係性を持つ」ようにするには 「ピボットテーブル」 などの表計算ソフトの機能が適切である場合があります。
- 時刻カラムを昇順にソートするには表計算ソフトのソート機能が有効です。
3. ETLツールを使う #
- ETL ツール とは、様々なデータソース(データベースなど)からデータを読み出し(Extract)、データに何らかの加工(Transform)を施し、別の場所に保存(Load)することができるソフトウェアのことを指します。
- ETLツールではプログラミング言語を使わず、 GUI で直感的にデータクレンジングの設定を行うことができるようになっています。
- 大規模なデータを扱う場合や、定期的に処理を行う必要がある場合は ETLツールの導入を検討してみてください
学習用データと予測用データ #
Node-AI で作成したモデルを実業務の課題に適用するには、新たなデータに対して 予測 (推論とも言う)を行うことにより未来の値を取得する必要があります。
予測を行うには
予測カード を使用するか、リアルタイム性が求められる場合は
推論API の構築を検討します。
予測カードの利用イメージについては
こちら もあわせてご確認ください。
ここでは予測カードを利用して予測を行う場合の、学習用データと予測用データの準備の方法について説明します。
データ形式とデータ量 #
学習用データと予測用データはどちらも本ページ冒頭で説明している “Node-AI で扱える時系列データの形式” である必要があります。
ただし以下の違いがあります。
- 学習用データには予測対象である 目的変数 のカラムが必要であるが、予測用データには目的変数カラムは含まれなくてよい。
- ただし予測用データに目的変数カラムが含まれない場合は、予測カードにおける可視化結果に目的変数の値が表示されません。
- 学習用データは
時間窓切り出し で設定する 窓幅 Mよりも十分大きなデータ量 が必要であるが、予測用データには 最低窓幅M のデータがあればよい。
- ただし、Node-AI では 未来Nの1時点の値を予測する ため、現在時刻から未来Nまでの連続的な区間の予測値が必要な場合、予測データは M+N のデータ量が必要です。
- また、予測カードにおける可視化結果を直感的に理解するには、ある程度過去のデータも含んでいるほうがよい場合があります。
これらをまとめると以下のようになります。
| 要件 | 学習用データ | 予測用データ |
|---|---|---|
| 目的変数カラム | 必要 | 任意 |
| データ量 | Mより十分大きな量 | 最低M |
例として、1日ごとのリンゴの売上数をデータとし、7日後のりんごの売上数を予測したいとします。
りんごの売上数はおよそ4週間前から現在の売上数により予測できると考えたあなたは、時間窓切り出しの窓幅Mを28と設定しました。
このとき、現在を 2023/04/01 だとすると以下のような学習用データが考えられます。
| Date | りんごの売上数 |
|---|---|
| 2022/04/01 | 320 |
| 2022/04/02 | 145 |
| … | … |
| 2023/03/30 | 213 |
| 2023/03/31 | 198 |
この1年分の学習用データを Node-AI にアップロードし、学習モデルの作成と評価まで実施します。
学習時、評価時には 2023/03/31 までの目的変数の値を正解値として構成されたデータによりモデルが作成されます。
次に、知りたいのは7日後の未来(2023/04/07)の値であるため、予測用のデータは以下のようなデータを用意します。
| Date | りんごの売上数 |
|---|---|
| 2023/03/03 | 132 |
| 2023/03/04 | 165 |
| … | … |
| 2023/03/30 | 213 |
| 2023/03/31 | 198 |
この場合は “りんごの売上数” が目的変数であると同時に説明変数にもなっているため、予測用のデータにも必須となります。
学習用データと異なる点として、予測用データは窓幅M(28日分)のデータのみでよいということです。
予測カードの実行により、以下のデータが取得できます。
| Date | 実測値 | 予測値 |
|---|---|---|
| 2023/03/03 | 132 | |
| 2023/03/04 | 165 | |
| … | … | |
| 2023/03/30 | 213 | |
| 2023/03/31 | 198 | |
| 2023/04/01 | ||
| 2023/04/02 | ||
| 2023/04/03 | ||
| 2023/04/04 | ||
| 2023/04/05 | ||
| 2023/04/06 | ||
| 2023/04/07 | 281 |
データ量がちょうど窓幅Mであるため、7日後の未来の予測値だけが取得できます。
2023/04/01~04/06 の予測値も欲しい場合、予測用データをさらに7日分増やし 2023/02/25 からのデータとします。
このとき予測カードにより以下が得られます。
| Date | 実測値 | 予測値 |
|---|---|---|
| 2023/02/25 | 281 | |
| 2023/02/26 | 190 | |
| … | … | … |
| 2023/03/30 | 213 | 230 |
| 2023/03/31 | 198 | 188 |
| 2023/04/01 | 221 | |
| 2023/04/02 | 137 | |
| 2023/04/03 | 110 | |
| 2023/04/04 | 223 | |
| 2023/04/05 | 331 | |
| 2023/04/06 | 187 | |
| 2023/04/07 | 281 |
この4/1~4/7のりんごの売上数の予測値に基づき、ビジネス課題の解決に使用します。
学習と予測のライフサイクル #
これまでの手順で、予測により未来の値を取得し、業務課題に適用することで何らかのインサイトを得たり業務フローの改善ができたとします。
しかし、一度予測をしてしまえば終わりということはなく、継続的に未来を予測し続けることを検討する段階に移ります。
前項の “りんごの売上数” のデータを例に考えましょう。
あなたは1週間後までのりんごの売上数の予測値を用いて発注量を最適化する改善案を実施し、実際に効果が得られることを確認したとします。
発注量の最適化は1週間単位で行えばよいとすると、次に予測を実行すべきなのは4/7までのデータが揃った段階となります。
4/8の時点では4/7のデータが得られているため、以下のようなデータが準備できます。
| Date | りんごの売上数 |
|---|---|
| 2023/02/25 | 281 |
| 2023/02/26 | 190 |
| … | … |
| 2023/03/30 | 213 |
| 2023/03/31 | 198 |
| 2023/04/01 | 210 |
| 2023/04/02 | 142 |
| 2023/04/03 | 118 |
| 2023/04/04 | 231 |
| 2023/04/05 | 307 |
| 2023/04/06 | 195 |
| 2023/04/07 | 266 |
4/1~4/7の売上数は、予測した値ではなく実際に売り上げた個数であることに注意してください。
予測モデルの予測値には必ず誤差が含まれるため、データとしては実測値を投入する必要があります。
| Date | 実測値 | 予測値 |
|---|---|---|
| 2023/02/25 | 281 | |
| 2023/02/26 | 190 | |
| … | … | … |
| 2023/03/30 | 213 | 230 |
| 2023/03/31 | 198 | 188 |
| 2023/04/01 | 210 | 221 |
| 2023/04/02 | 142 | 137 |
| 2023/04/03 | 118 | 110 |
| 2023/04/04 | 231 | 223 |
| 2023/04/05 | 307 | 331 |
| 2023/04/06 | 195 | 187 |
| 2023/04/07 | 266 | 281 |
| 2023/04/08 | 156 | |
| 2023/04/09 | 271 | |
| 2023/04/10 | 229 | |
| 2023/04/11 | 167 | |
| 2023/04/12 | 335 | |
| 2023/04/13 | 267 | |
| 2023/04/14 | 312 |
4/8~4/14の売上数の予測値が得られました。学習したモデルをそのまま使う場合は、4/1~4/7の予測値は変わっていません。
さて、この方法でも繰り返し予測を行うことで継続的に業務適用はできますが、「4/7までの実測値は得られているので、4/7までのデータを使ってモデルを再度学習させればより精度が出るのではないか」という仮説が立てられます。
この仮説は正しい場合もあれば、誤っている場合もあります。一般にデータ量を増やせばモデルの精度は上がる可能性はありますが、それはデータに依存しています。
仮に4/7までのデータを使って再学習したとしても、4/1~4/7のデータが特殊な特徴を持っているかもしれません。
例えば4/1~4/3の期間に、これまで実施したことがない大規模セールを打っていたとしましょう。今後このような同様のセールを行わないのであれば、学習用データに含めることでノイズとなる可能性があります。
一方、これは一つの考え方に過ぎず、「セールを打つ」という特徴を新たに説明変数として追加することの契機であるかもしれません。
このように、学習用データと予測用データは常にアップデートするかを検討しながら継続的にモデルの作成と予測の実行を繰り返す必要があります。