4.1.c. 決定木回帰モデルの設計 #
4.1.c.1. 機能概要 #
決定木回帰モデルを設計します。決定木モデルとは、データを階層的に分割し、「YES」か「NO」の質問によってデータを分類・予測するモデルです。
例えば、気温からアイスの売上価格を予測するために下図のような簡単なデータを考えます。さらに下図の散布図では、気温でデータをグループ分けをすることを考え、3本の線によりデータを4つのグループに分けています。このとき、各グループごとの売上価格の平均値を予測値とするモデルが決定木回帰モデルです。
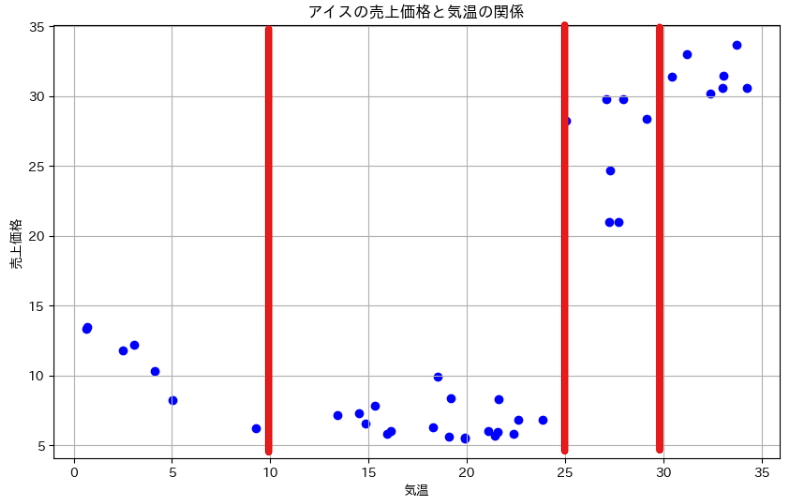
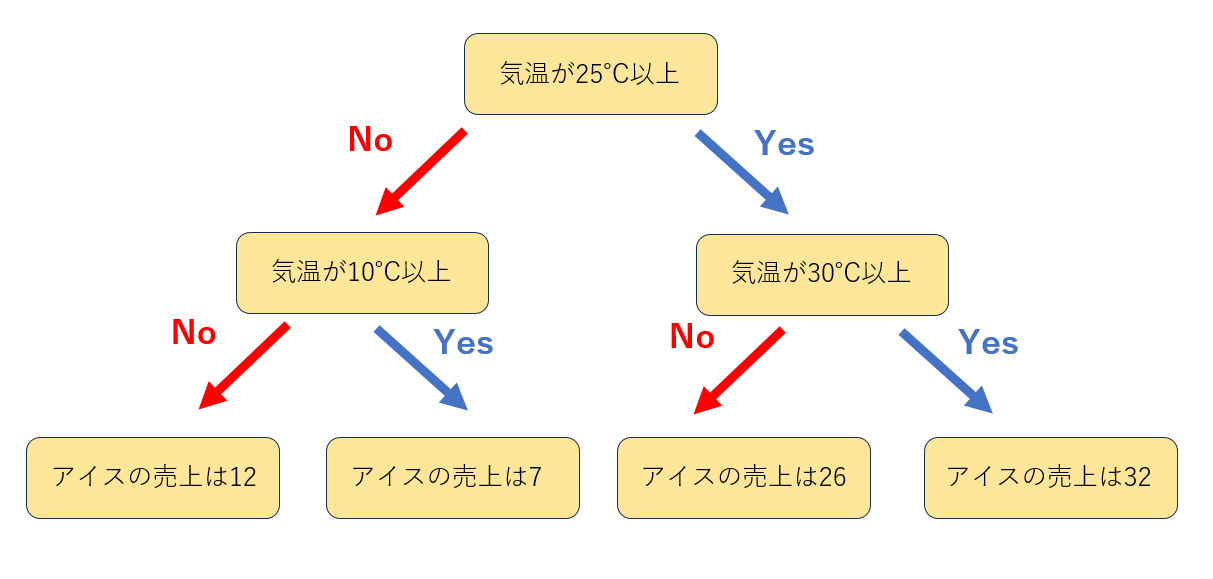
つまり、下図のような木を構成することによって「気温が10度以上25度未満ならばアイスの売上価格は約7」、「気温が30度以上ならばアイスの売上価格は約32」のように売上価格を予測することができます。
4.1.c.2. 入力と出力 #
なし
| 種別 | 接続先 |
|---|---|
| 設計済みモデル | 学習 |
4.1.c.3. 操作方法 #
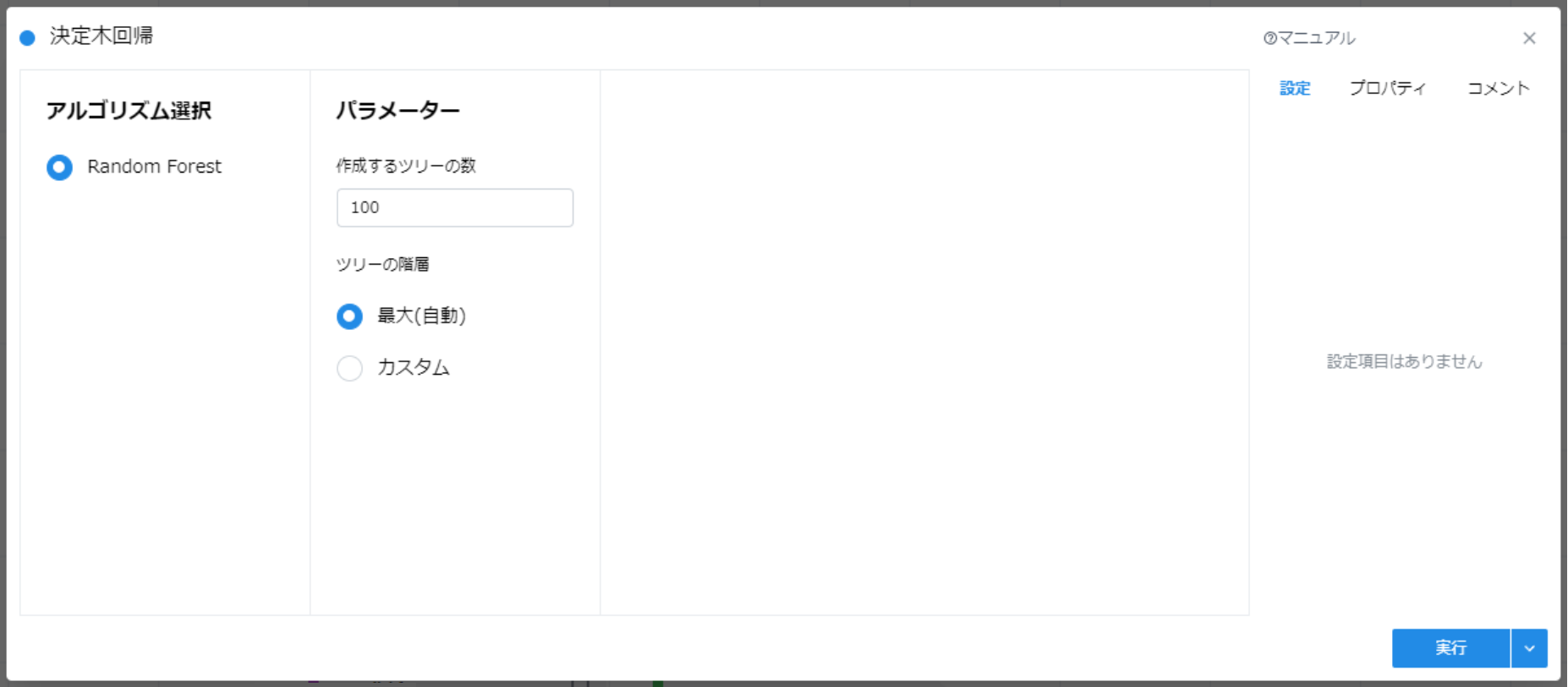
4.1.c.3.1. アルゴリズムの選択、各種パラメータの設定 #
各アルゴリズムで設定が必要となるパラメータは以下です。
| アルゴリズム名 | 概要 | パラメータ |
|---|---|---|
| Random Forest | 決定木を弱学習器とするアンサンブル学習アルゴリズム(複数の決定木モデルを作成して出力の平均値をとる手法)。説明変数が多数であってもうまく動くことが多い。 | 作成するツリーの数, ツリーの階層 |
各アルゴリズムのパラメータの説明は以下です。
- Random Forest
- 作成するツリーの数
- ツリーの数(n_estimators)を指定する
- 数が多いほど精度が高くなるが、過学習が起きる可能性が高くなる
- ツリーの階層
- ツリーの深さ(max_depth)を指定する
- 数が多いほど複雑なデータを近似できるが、過学習が起きる可能性が高くなる
- 作成するツリーの数
4.1.c.3.2. 設計の保存 #
- “実行” ボタンを押して、設定を保存します。
- 設定内容に矛盾が存在する場合は、エラーが表示されます。
- 処理時間が 5 分を超えるとタイムアウトし、処理が強制終了されます。